

The implementation of a data vault architecture requires the integration of multiple technologies to effectively support the design principles and meet the organization’s requirements. In data vault implementations, critical components encompass the storage layer, ELT technology, integration platforms, data observability tools, Business Intelligence and Analytics tools, Data Governance, and Metadata Management solutions.
It is crucial to consider various factors, such as the organization’s existing technology stack, budget, scalability needs, and skill sets when making technology choices and designing the overall architecture.
In this blog, our focus will be on exploring the data lifecycle along with several Design Patterns, delving into their benefits and constraints. Data architects can leverage these patterns as starting points or reference models when designing and implementing data vault architectures.
What Are Data Vault Design Patterns?
Data Vault Design Patterns are reusable solutions or best practices for modeling and implementing data vault architectures. Designing an appropriate architecture and choosing the right technologies considering an organization’s specific needs is critical to address challenges like performance, scalability, flexibility, and data integrity.
Data Vault - Data Lifecycle
Architecturally, let’s understand the data lifecycle in the data vault into the following layers, which play a key role in choosing the right pattern and tools to implement.
Data Acquisition: Extracting data from source systems and making it accessible.
Loading & Staging: Moving the source data into the data warehouse. The data is immutable and should be stored as it was received from the source. From a data vault perspective, functionally, this layer is also responsible for adding technical metadata (record source, load date timestamp, etc.) as well as calculating business keys.
Raw data vault: Raw Vault is created from the landing or staging zone. Data is modeled as Hubs, Links, and Satellite tables in the Raw data vault.
Business data vault: Data vault objects with soft business rules applied. This could also optionally include PIT and Bridge tables created for the presentation layer on top of the business vault.
Information Mart: A layer of consumer-oriented models. This could be implemented as a set of views. It is common to see the use of dimensional models (star/Snowflake Data Cloud) or denormalized for your end users.

Implementing Data Vault with DBT and Snowflake

The core data vault entities are hubs, links, and satellites. That said, dbt provides the ability to generate data vault models and also allows you to write your data transformations using SQL and code-reusable macros powered by Jinja2 to run your data pipelines in a clean and efficient way.
The most important reason for using DBT in Data Vault 2.0 is its ability to define and use macros. Macros can be called in models and then generated into additional SQL snippets or even the entire SQL code.
When the model is executed, dbt generates the whole SQL out of the macro and decides how the records are loaded. If the hub/satellite or link table does not exist, it is created, and all records are loaded. If they already exist, then the tables are loaded incrementally.
Managing a data vault with SQL is a real challenge. Having automation in place, the team can now focus entirely on the data vault design itself. Once the metadata is identified, dbt, along with your macros, can take care of the entire logic. Also, using Snowflake streams as a source ensures seamless near real-time data processing.
1. AutomateDV is a dbt package in which you can Define the staging model, create models that extract and load data into hub tables, Define models for link tables that capture the relationships between hubs, and create models to load satellite tables that store descriptive attributes and historical changes.
2. Implement incremental loading: Data Vault promotes the concept of loading only the changed or new records into the satellite tables. Utilize dbt’s incremental materialization to process new feeds from Snowflake streams or implement any intermediary Ephemeral models in dbt to achieve the same.
3. Implement business rules and validations: Data Vault models often involve enforcing business rules and performing data quality checks. Leverage dbt’s `test` macros within your models and add constraints to ensure data integrity between data vault entities.
4. Maintain lineage and documentation: Data Vault emphasizes documenting the data lineage and providing clear documentation for each model. Utilize dbt’s built-in documentation features, such as descriptions and YAML metadata, to annotate your models and provide context for users.
There are a number of advantages to using open-source packages like AutomateDV. Due to the fact that the structure of the data vault is exclusively metadata-driven by the package, errors that occur when writing SQL statements manually can be minimized. If there are changes in the data structure, these can be adjusted centrally without examining huge amounts of SQL statements for dependencies.
This means that it is possible to build better pipelines with fewer integration errors, allow easier understanding of the ELT process, and simplify maintainability. To understand more about AutomateDV, visit phData’s blog.
Implementing Data Vault Using Snowflake Native Components
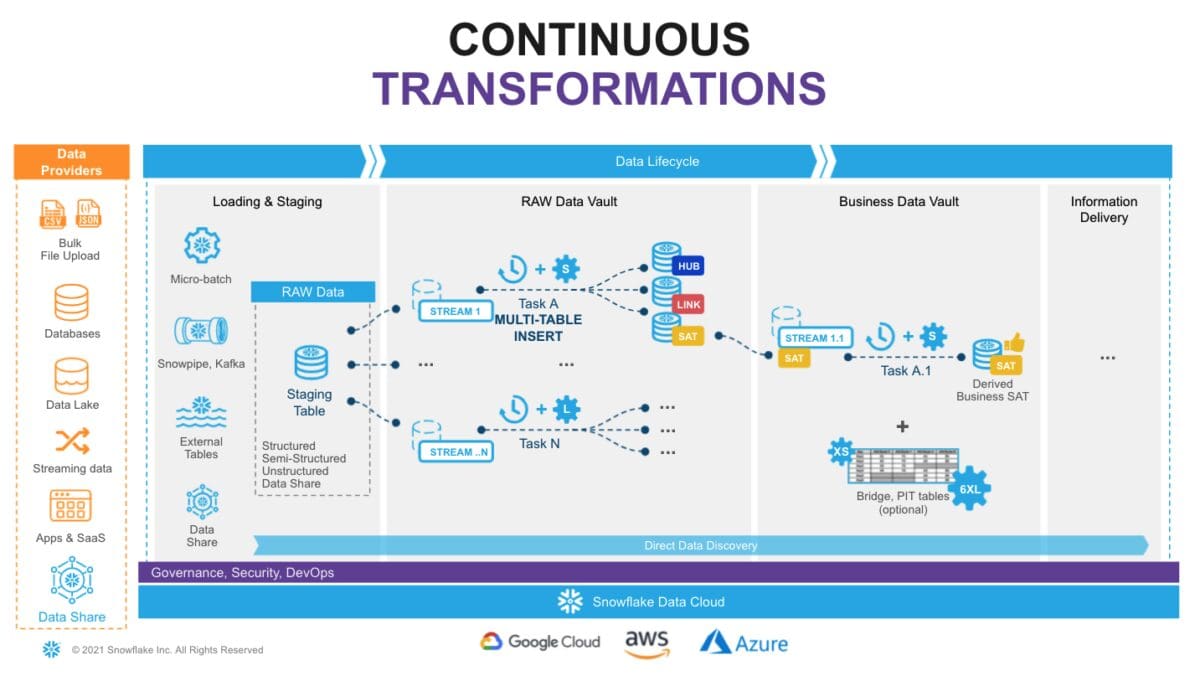
Snowflake offers various options for building data pipelines. Let’s explore one of the methods for implementing near real-time (NRT) data vaults using Snowflake Continuous Data Pipelines.
Snowflake’s stream object tracks all data changes on a table (inserts, updates, and deletes). This process is fully automatic and, unlike traditional databases, will never impact the speed of data loading. The changelog from a stream is automatically ‘consumed’ once a successfully completed DML operation uses the stream object as a source.
Snowflake Tasks are set to execute at defined intervals to check if there is any data in the associated stream. If data exists, the tasks execute SQL statements to push it into the Raw data vault objects. Tasks can be organized in a dependency graph, executing child tasks once their predecessor has completed its portion.
Furthermore, to adhere to Data Vault 2.0 best practices for NRT data integration, we leverage Snowflake’s multi-table insert (MTI) capability within tasks. This allows us to populate multiple raw data vault objects like Hubs, Links, and Satellites with a single DML operation. Alternatively, you can create multiple streams and tasks from the same staging table to populate each data vault object using separate asynchronous flows.
Tasks with multi-cluster virtual warehouses will have sufficient computing power to handle workloads of any size, and load balances all the tasks as you introduce more hubs, links, and satellites to your data vault. In addition to tasks, Snowflake has serverless tasks, a fantastic capability that allows you to rely on compute resources managed by Snowflake.
As your raw data vault is updated, the streams can be leveraged to propagate those changes to Business Vault objects, such as Point-in-Time tables (PITS) or Bridges, if necessary, in the subsequent layer.
By following this approach, you can establish a production data pipeline that seamlessly feeds your data vault architecture, requiring minimal manual intervention.
Source: Snowflake
Necessity For a Strong Data Quality Framework
Though there are many benefits to data vault architecture, it also comes with certain challenges, such as more tables with complex transformations and relationships between upstream and downstream. This can create data quality challenges if not addressed properly.
Having model-level data validations along with implementing a data observability framework helps to address the data vault’s data quality challenges.
One of the hallmarks of data vault architecture is that it “collects 100% of the data 100% of the time,” which can make correcting bad data in the raw vault a pain. The data observability mechanism reduces time to detection to enable data teams to close the spigot of broken pipelines and stop the flow of bad data flowing into the raw vault, thereby reducing the data backfilling burden.
From raw data landing zones down to reporting tables, data observability solutions can make sure that your range of numbers and types of values are as expected.
Transformation queries that move data across layers are monitored to make sure they run at the expected times with the expected load volumes, defined in either rows or bytes.
Finally, a data observability framework should also be easy to implement across your entire stack and continue to monitor beyond the initial implementation so that future satellites and hubs that are added in the future can be certified as safeguarded.
Open sources dbt packages such as elementary, dbt_expectations, or any other platforms such as SODA could be considered.
Data Vault Automation
Working at scale can be challenging, especially when managing the data model. This is where automation tools come into play. Automations provide extra support to small teams by having templates to automate data integration, data vault modeling, and ETL/DDL code generation. Leading to significant productivity gains. Automation also helps to address key challenges, such as
Code maintenance
Multiple, complex transformations between layers
Maintaining integrity across the hub, link, and satellite tables
Understanding dependencies
Scaling testing scenarios
Open sources dbt packages such as AutomateDV or any other tools such as WhereScape Data Vault Express, Erwin Data Vault Automation, etc.. could be considered to automate data vault design and development.
Best Practices and Pitfalls to Avoid in Data Vault 2.0 Projects
Design for Scalability and Flexibility: Data Vault 2.0 is designed to accommodate changing business requirements and handle large volumes of data. To name a few:
Segregating the satellites based on the rate of change or information group.
Deciding on the layer of business rule implementation at the Business vault or information mart, or BI tools layer.
Having PIT, Bridge tables, or helper tables as required based on query performance.
Modeling Decisions: One needs to identify what things the business needs to know to succeed. There may be different answers to different projects, depending on the analyst. For example, a modeler may make decisions early about entities such as customers.
Use Automation Tools: Leverage automation tools to generate data vault structures, as manual implementation can be time-consuming and error-prone. Data vault modeling is a repeatable pattern for data modeling tools that can help generate code, enforce naming conventions, and maintain consistency across the data model. Automate and prioritize Test Driven Development (TDD) for data vault projects.
Establish Consistent Naming Conventions and Standards: Consistency in naming conventions is crucial for maintaining clarity and ease of understanding. Use standardized naming patterns for hubs, links, satellites, and their attributes to ensure consistency across the entire data model. Use a conceptual data model (CDM) to capture the taxonomy and ontology after consulting the business experts.
Implement Data Lineage and Traceability Path: Data Vault 2.0 emphasizes the ability to trace data back to its source. Maintain detailed documentation and metadata to track the origins of data and establish data lineage. This enables better data governance, auditing, and compliance. Something similar to dbt Lineage graphs.
Establish Data Quality Checks: Implement data quality checks and validation rules to ensure the accuracy and reliability of data stored in the data vault. This includes checks for data completeness, consistency, conformity, and timeliness. You shall implement dbt packages like dbt Constraints or implement several dbt tests on data vault models.
Maintain Documentation and Metadata: Document the data model, its relationships, and transformations. Additionally, maintain metadata to provide comprehensive information about the data elements, sources, and transformations. This documentation facilitates easier maintenance, troubleshooting, and onboarding of new team members.
Conclusion
We saw how modern tech stacks like Snowflake and dbt could be leveraged to implement data vaults for organizations. There are a range of automation tools available to support your project. It’s also worth ensuring that you have a sound understanding of the method before starting to avoid rookie mistakes.
By implementing the best practices, you can create a robust, scalable, and flexible data vault model that meets your business needs. It’s essential to keep the model as simple as possible, business-driven, and thoroughly tested. The importance of selecting the right design pattern for your organization’s needs is emphasized, as it impacts scalability, flexibility, and ease of maintenance.
Looking for more assistance in setting up a data vault architecture with dbt and Snowflake? Reach out to our team of experts today!









