When looking to build out a new data lake, one of the most important factors is to establish the warehousing architecture that will be used as the foundation for the data platform.
While there are several traditional methodologies to consider when establishing a new data lake (from Inmon and Kimball, for example), one alternative presents a unique opportunity: a Data Vault.
Utilizing a Data Vault architecture allows companies to build a scalable data platform that provides durability and accelerates business value.
Here’s how:
What is a Data Vault?
After trying and failing to implement a large-scale data warehouse with existing architectures, Dan Linstedt and his team at Lockheed Martin created the Data Vault methodology in the early ’90s to address the challenges they had faced.
At its core, Data Vault is a complete system that provides a methodology, architecture, and model to successfully and efficiently implement a highly business-focused data warehouse. There are many ways these various components can be utilized and implemented, however, it’s important to stick to and follow the standard recommendations of the Data Vault system when building a Data Vault. Projects can quickly become unsuccessful if the standards are not followed.
Pros and Cons of Using a Data Vault
Let’s take a closer look at a few of the reasons why we would want to design a data lake using Data Vault — and some of the potential drawbacks to consider.
Pros
- Insert only architecture
- Historical record tracking
- Keeps all data; the good and the bad
- Provides auditability
- Can be built incrementally
- Adaptable to changes without re-engineering
- Model enables data loads with a high degree of parallelism
- Technology agnostic
- Fault-tolerant ingestion pipelines
Cons
- Models can be more complex
- Teams need additional training to know how to correctly implement a Data Vault
- Amount of storage needed to maintain complete history
- Data isn’t immediately user-ready when it’s ingested into the Data Vault (business vault and information marts need to be created to provide value to the business)
3 Core Data Vault Modelling Concepts
There are three core structures that make up a Data Vault architecture:
- Hub
- Link
- Satellite
As we step through the structures below, take note of the required fields — these are mandated by the Data Vault architecture. While the hashing applications described below are not technically mandated, Data Vault 2.0 highly recommends them. Hashing provides many advantages over using standard composite or surrogate keys and data comparisons:
- Query Performance – Fewer comparisons to make when joining tables together.
- Load Performance – Tables can be loaded in parallel because ingestion pipelines don’t need to wait for other surrogate keys to be created in the database. Every pipeline can compute all the needed keys.
- Deterministic – Meaning that the key can be computed from the data. There are no lookups necessary. This is advantageous because any system that has the same data can compute the same key.
- Business hashes can be used to better distribute data in many large distributed systems.
- Content hashes can efficiently be used to detect changed records in a dataset no matter how many columns it contains.
- Data Sharing – Hashed keys can enable high degrees of sharing for sensitive data. Relationships between datasets can be exposed through Link tables without actually exposing any sensitive data.
Note: all of the structures listed below are non-volatile. This means that you can’t modify the data in the rows. If there needs to be an update to a row, a new row must be inserted into the table which would contain the change.
Hub
A Hub represents a core business entity within a company. This can be things like a customer, product, or a store.
Hubs don’t contain any context data or details about the entity. They only contain the defined business key and a few mandated Data Vault fields. A critical attribute of a Hub is that they contain only one row per key.

Link
A Link defines the relationship between business keys from two or more Hubs.
Just like the Hub, a Link structure contains no contextual information about the entities. There should also be only one row representing the relationship between two entities. In order to represent a relationship that no longer exists, we would need to create a satellite table off this Link table which would contain an is_deleted flag; this is known as an Effectivity Satellite.

One huge advantage Data Vault has against other data warehousing architectures is that relationships can be added between Hubs with ease. Data Vault focuses on being agile and implementing what is needed to accomplish the current business goals. If relationships aren’t currently known or data sources aren’t yet accessible, this is ok because Links are easily created when they are needed. Adding a new Link in no way impacts existing Hubs or Satellites.
Often, with more traditional approaches, these kinds of changes can lead to larger impacts on the existing model and data reloads. This is one of the factors that makes Data Vault modeling an agile and iterative process. Models don’t have to be developed in a “big bang” approach.
Satellite
In Data Vault architecture, a Satellite houses all the contextual details regarding an entity
In my business, data changes very frequently. How can non-volatile contextual tables work for me?
When there is a change in the data, a new row must be inserted with the changed data. These records are differentiated from one another by utilizing the hash key and one of the Data Vault mandated fields: the load_date. For a given record, the load_date enables us to determine what the most recent record is.

In the example above, we see two records for the same product_hash. The most recent record, which is defined by the load_date, corrects a spelling error in the product_name field.
But won’t that take forever to determine what has changed between the source and the Data Vault?
No — this is very performant with the use of a content_hash. While it’s optional with a Data Vault model, it provides a huge advantage when examining records that have changed between source and target systems.
The content_hash is computed when populating the Data Vault Staging area (more on this below), and it would utilize all relevant contextual data fields. When any of these contextual data fields are updated, a different content_hash would be computed. This allows us to detect changes very quickly. Depending on the technology in use, this would most commonly be accomplished with an Outer Join, although some systems offer even more optimized techniques.
To help with differentiation, Satellites are created based on data source and its rate of change. Generally, you would design a new Satellite table for each data source and then further separate data from those sources that may have a high frequency of change. Separating high and low-frequency data attributes can assist with ingestion throughput and significantly reduce the space that historical data consumes. Separating the attributes by frequency isn’t required, but it can offer some advantages.
Another common consideration when creating Satellites is data classification. Satellites enable data to be split apart based on classification or sensitivity. This makes it easier to handle special security considerations by physically separating data elements.
What Does a Data Vault Look Like?
If you’ve worked with a more traditional data warehousing model, dimension modeling and star schemas will be very familiar to you.
In a simplified example of star schema (a sales order for a retail establishment) you may end up with something like this:
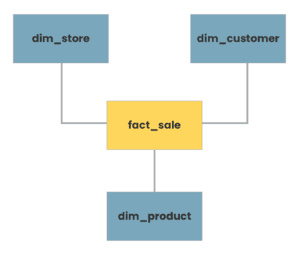
Taking our Data Vault concepts from above and applying them to our same example, we may instead end up with something like this:

We can see right away that we gained a few tables over our star schema example. We no longer have a single Dimension table representing Customer, but we have replaced that with a Customer Hub table and two Satellite tables. One Satellite contains data from a retailer’s Salesforce instance, while the other contains data from the retailer’s webstore.
In short, the Data Vault methodology permits teams to ingest new data sources very quickly.
Instead of reengineering the model and wasting valuable cycles determining the impact of those changes, data from a new source can be ingested into a completely new Satellite table. This speed also enables data engineers to iterate rapidly with business users on the creation of new information marts.
Need to integrate completely new business entities to the Data Vault? You can add new Hubs at any time, and you can define new relationships by building new Link tables between Hubs. This process has zero impact on the existing model.
A Modern Data Platform Architecture

Staging
Staging is essentially a landing zone for the majority of the data that will enter the Data Vault.
It often doesn’t contain any historical data, and the data mirrors the schema of the source systems. We want to ingest data from the source system as fast as possible, so only hard business rules are applied to the data (i.e. anything that doesn’t change the content of the data).
The Staging area can also be implemented in what is known as a Persistent Staging Area (PSA). Here, historical data can be kept for some time in case it is needed to resolve issues or referenced back to. A PSA is also a great option to use as a foundation for a Data Lake! You won’t want all use-cases hitting your enterprise data warehouse (EDW), so having a PSA/Data Lake is a great capability to enable Data Science, Data Mining, and other Machine Learning use-cases.
Ideally, the pipelines that ingest data into Staging should be generatable and as automated as possible. We shouldn’t be wasting a lot of time ingesting data into the Data Vault. Most of our time should be spent working with the business and implementing their requirements in Information Marts.
Enterprise Data Warehouse
Raw
Raw is where our main Data Vault model lives (Hubs, Links, Satellites).
Data is ingested in the Raw layer directly from the Staging layer, or potentially directly into the Raw layer when handling real-time data sources. When ingesting into the Raw layer, there should also be no business rules applied to the data.
Ingesting data into Raw is a crucial step in the Data Vault architecture and must be done correctly to maintain consistency. As was mentioned earlier for Staging, these Raw ingestion pipelines should be generatable and as automated as possible. We shouldn’t be handwriting SQL statements to do the source to target diffs. One incorrect SQL statement and you will have unreliable and inconsistent tables. The genius of Data Vault is that it enables highly repeatable and consistent patterns that can be automated and make our lives a lot easier and more efficient.
Business Vault
The Business Vault is an optional tier in the Data Vault where the business can define common business entities, calculations, and logic. This could be things like Master Data or creating business logic that is used across the business in various Information Marts. These things shouldn’t be implemented in every information mart differently, it should be implemented once in the Business Vault and used multiple times through the Information Marts.
Metrics Vault
The Metrics Vault is an optional tier used to hold operational metrics data for the Data Vault ingestion processes. This information can be invaluable when diagnosing potential problems with ingestion. It can also act as an audit trail for all the processes that are interacting with the Data Vault.
Information Delivery
Information Marts
The Informational Marts are where the business users will finally have access to the data. All business rules and logic are now applied into these Marts.
For implementing business rules and logic, the Data Vault Methodology also leans heavily on the use of SQL Views over creating pipelines. Views enable developers to very rapidly implement and iterate with the business on requirements when implementing Information Marts. Having too many pipelines is also just more things to maintain and worry about rerunning. Business users can query Views knowing they are always accessing the latest data.
So does this mean I have to fit all my business logic into Views now?
No — The preference of the Data Vault methodology leans towards using Views, but there are certain things Views aren’t the right fit for (i.e. extremely complex logic, machine learning, etc.). If it feels like a struggle trying to get SQL to perform your business logic, a View probably isn’t the right tool. For these cases, a traditional pipeline is going to be your best bet.
If all my business logic is in Views, isn’t that going to slow down my BI reports?
Like anything else, it depends. There are many considerations from the size and volume of the data, the complexity of the business logic, to the database technology and capabilities of that system.
Most times Views will perform just fine and meet the needs of most business needs. If, however, Views aren’t performing for your use-case, the Data Vault methodology offers more advanced structures known as Point In Time (PIT) and Bridge tables which can greatly improve join performance. As a last resort, Data Vault methodology states we can materialize our data (i.e. materialized view or new table).
The concept of an Information Mart is also a logical boundary. Your Data Vault can also be used to populate other platform capabilities such a NoSQL, graph, and search. These can still be considered as a form of information mart. These external tools would typically be populated using ETL pipelines.
Error Marts
Error Marts are an optional layer in the Data Vault that can be useful for surfacing data issues to the business users. Remember that all data, correct or not, should remain as historical data in the Data Vault for audit and traceability.
Metrics Marts
The Metics Mart is an optional tier used to surface operational metrics for analytical or reporting purposes.
Moving Forward With Your Data Platform
Choosing the right warehousing architecture for your enterprise isn’t only about ease of migration or implementation.
The foundation you build will either support or inhibit business users and drive or limit business value. Utilizing Data Vault may not be traditional, but it could be exactly what you need for your business.
Looking for More Information on Implementing a Data Vault?
We know it can be a challenge to build a data platform that maintains clean data, caters to business users, and drives efficiency.
If you have more questions or don’t quite know where to get started with building or managing a data platform using Data Vault, please reach out and talk to one of our experts!


