

This blog was co-written by Dakota Kelley and Troy Fokken.
dbt Coalesce 2023 marked the unveiling of an exciting new set of functionality for dbt Cloud, dbt Mesh. We are very excited about this new suite of capabilities and what it means for our customers and the broader dbt community.
In this blog, we’ll explore what dbt Mesh is, why it’s important, and how to adopt it for your organization.
What is dbt Mesh?
dbt Mesh is a new architecture that allows organizations to facilitate cross-team collaboration, ship data applications faster, and build trust with data.
Before dbt Mesh, phData customers would build out monolithic dbt repositories inclusive of all models to produce a complete lineage on the data platform. If the organization were large enough to necessitate a multi-repo project, standards would be built, but everything still needed to be combined to get full lineage and proper documentation.
With dbt Mesh, we can see that dbt is embracing a Data Mesh Architecture that will simplify how a large enterprise manages dbt thanks to the implementation of Data Contracts.
dbt Project Architectures
Before we dive too deep into dbt Mesh and Data Contracts, let’s first cover what the two common repositories structures and architectures are. We will focus on high-level architectural decisions that drive the two, plus the pros and cons.
Mono Repository
Mono repositories are the most common setup, especially as teams first begin learning about dbt. Usually, the initial team is working through a proof-of-concept with dbt, and they’re learning how it works and making sure they like the new paradigms that dbt brings to their data stack.
However, as time moves forward and more people begin to onboard into this repository, it becomes difficult to meet everyone’s needs, especially in large enterprises with many different teams of developers.
Here are the pros and cons of a mono repo:
Pro
Easy to share and maintain business logic.
Full dependency lineage and documentation.
One-stop shop for viewing all models and tests.
Easier to implement large-scale changes without breaking existing models.
Con
Hard to manage across disparate teams thanks to too many chefs in the kitchen.
CI/CD workflows and scheduling conflicts due to uncertainty on who should be reviewing which pull requests.
Too many models as more teams onboard, making the project extremely daunting for new members.
Cross-team/domain release process and coordination.
Code management and git version control between branches can become complicated.
Change A can be released but change B cannot.
Causes the need to cherry-pick commits or coordinate branches being merged.
Package changes affect all models.
Multi Repository
Larger organizations that have either outgrown the mono repo, or built for scale in the first place would frequently pick multi repo architectures that allowed them to simplify workflows and make sure that teams only had access to what was important to them.
However, sharing business logic between repositories, or tracking the full lineage across multiple projects wasn’t always the easiest.
Here are the pros and cons of a multi repo:
Pro
Easy to address security and model ownership.
Easy to onboard teams into narrower scoped projects.
Easier approval workflows, and CI/CD that matches your teams needs.
Each repository can manage their own dependencies and versions.
Con
Maintaining full documentation and lineage becomes a more involved process.
Sharing business logic isn’t always the easiest.
Drift between packages, versions, and standards across projects (without introducing additional complexity).

How did Teams Address this Before?
To try and accomplish the best of both worlds, teams would try to build local packages of shared business logic and rules. However, when making changes, it was difficult to test all of the disparate projects.
Also, at the end of the entire process, all of the projects need to be pulled into one large project to get the full lineage, which was always cumbersome and difficult to manage. Additional packages and shared utilities would get promoted from single projects to shared packages installed on each project.
You’d also frequently run into situations where Team A updated a model that caused issues for Team B.
As you can see, the more the repositories grow, the more cumbersome this process becomes. Thankfully, dbt Labs has been listening, and the solution is building data mesh functionality into dbt. One of the core structures within data mesh, or dbt Mesh as it is being called, is a Data Contract.
What Are Data Contracts?
Data Contracts provide a way for teams as data producers to contract out what data is available. It acts as a way to provide a service level agreement to a data model that is heavily used and should be shared across different projects. The contract, when enforced, will monitor the shape of your data to make sure it hasn’t unexpectedly changed.
Data Contracts act as a test to alert you when a change to a data product has occurred and if it could impact others. When there is a necessary change to the underlying model, we now also have access to the ability to version our models allowing us to maintain the old unchanged version until a deprecation date is reached while alerting teams in their own projects that they are dependent on a deprecated model and should move to the updated model.
This allows for a proper process to simplify how changes cascade to others and makes sure appropriate processes exist to address changes that could impact others. Below you’ll find an example of the definition of a Data Contract:
models:
- name: dim_customers
config:
materialized: table
contract:
enforced: true
columns:
- name: customer_id
data_type: int
constraints:
- type: not_null
- name: customer_name
data_type: string
- name: non_integer
data_type: numeric(38,3)
On top of this, dbt has also provided the ability to create model governance structures that permit you to define access (public/private) and groups—allowing us to designate how much of our project others can see, and who has access to what models we do make public.
With all of these things established in our project, dbt Cloud allows us to easily reference to other projects within our organization through the definition of a dbt project dependency like so:
packages:
- package: dbt-labs/dbt_utils
version: 1.1.1
projects:
- name: jaffle_finance # matches the 'name' in their 'dbt_project.yml'
This makes it easy to designate what other projects we are dependent on as well as any packages within a singular dependency.yml file. Once the dependencies are established, other project models can be referenced by fully qualifying the ref function to the project like so:
with monthly_revenue as (
select * from {{ ref('jaffle_finance', 'monthly_revenue') }}
),
...
Cross-Project Lineage
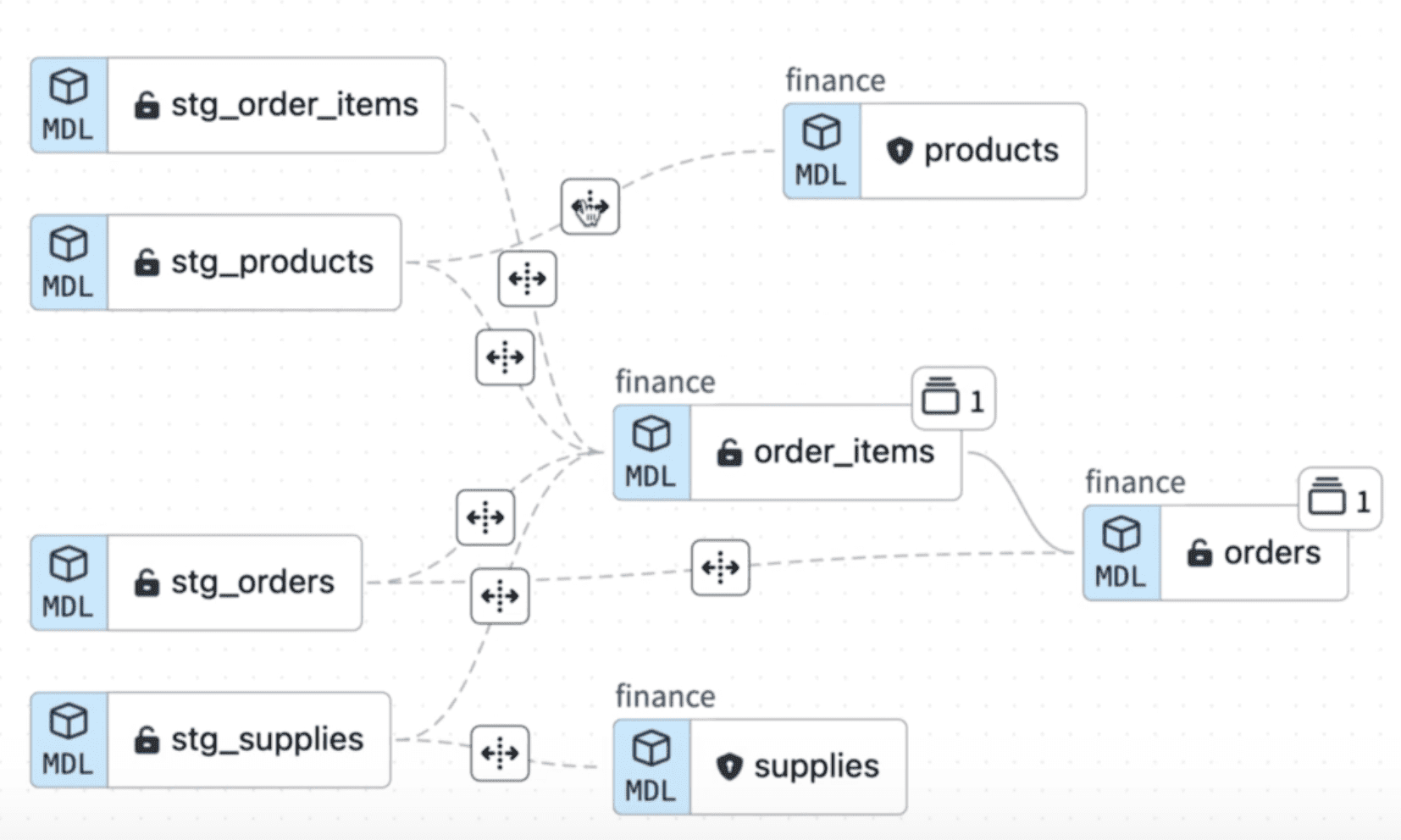
During dbt execution, numerous project artifacts are generated, detailing the diverse models and control structures in place. Enter the impressive dbt Explorer, a feature that aggregates these artifacts from multiple projects, offering a comprehensive view of the entire cross-project lineage. This enables teams to access models shared with them and provides administrators with a unified, extensive lineage graph.
Additionally, dbt Explorer facilitates data democratization, ensuring complete transparency of data assets, and supports the adoption of a Data Mesh architecture, harmonizing repositories across various business units and teams.
How to Adopt dbt Mesh
After seeing these features in action, you might be wondering how to best adopt dbt Mesh within your organization? This comes down to a three step process: Planning, Implementation, and Validation. Within these steps things may change based on decisions already made by the organization and project architecture used.
Planning
To begin, start by understanding the current repository structure. Is everything built as a mono repo or multi repo? Use this to help drive where things need to be separated. Work with business architects to understand the various data domains, working structures, functional teams, business owners, and data stewards as this will help you decide what and how to contract data.
Then, identify how you want to structure dbt projects going forward and finally, document how you want to create data contracts within dbt.
Spending time planning these activities allows you to move quickly while identifying who will support which contracts and where— allowing the organization to update support processes and governance controls around them.
With all of these things decided, it is time to begin implementation.
Implementation
With everything planned out, it is time to begin implementing the dbt Mesh features. This may include any of the following activities:
Create new git repository to dbt project alignment.
Create new Active Directory groups and assign functional team membership.
Initialize new dbt project(s).
Create dbt cloud projects.
Configure git repository.
Migrate dbt models to project-specific repositories.
Establish new schedules for project-specific model creation.
Identify project-specific support teams and grant access to job executions.
The activities will vary and depend on the current architecture. If projects are already split into a multi repo, instead, the team can focus on adding contracts and simplifying the governance and process to make sure that dependent projects do not impact each other (while mono repos will need to do all of the activities).
Automation
If the organization has a lot of work needed to build out and make use of dbt Mesh, remember automation does exist to help speed up implementation through the dbt Meshify project. This allows the team to focus on the planning steps so it can move quickly to implement within the organization’s dbt projects.
Validation
Finally, the organization should spend time auditing and verifying results to make sure everything is running smoothly. This can be done with various tools including phData’s own Data Source tool to run comparisons to the results before and after.
Conclusion
dbt Mesh signifies a major advancement for dbt Cloud users and the broader dbt community. It revolutionizes cross-team collaboration, accelerates data application deployment, and builds trust with data, steering away from monolithic dbt repositories towards a more manageable, Data Mesh Architecture.
If your organization is looking to succeed with dbt, phData would love to help!
As dbt’s 2023 Partner of the Year, our experts will ensure your dbt instance becomes a powerful transformation tool for your organization.









