

How to Run dbt Models in Different dbt Project Structures
Within any organizational structure, the most common decision that needs to be made is whether you want a centralized or decentralized model. There are pros and cons to both of these options (and there are hybrid approaches out there as well), but what does this actually mean?
Organizations that are centralized rely on a single leader, team, or business function to make decisions regarding strategic planning, goal setting, budgeting, and tooling that’s available to the broader organization.
This creates a single “hub” where all decisions are made and the owner of that decision has visibility into all the requirements that are inputs to the decision at the cost of being further from customers, slower decision making, and complicated prioritization.
An example of this would be a “central” IT where business units request features and functionality to be serviced by the one IT unit.
Organizations that are decentralized distribute formal decision-making power to multiple individuals or teams. This allows for different pieces of the organization to make decisions and prioritize based on their specific needs but lacks a centralized authority having visibility into all the processes and decisions.
An example of this would be each business unit having their own IT department or engineers whose job is to only service features and functionality from their specific business unit.
When deciding to leverage dbt for your data needs, this is one of the first decisions that your need to make when setting up your dbt project.
Let’s take a look at the different approaches for structuring dbt projects.
Centralized dbt Project
This is the default approach for many examples you’ll see online since it’s the simplest. Organizations can take the centralized approach and have one dbt project that contains all of the analytics engineering needs such as data modeling, data quality testing, and metrics defined in one location.
This gives the entire organization the ability to see all of the transformations, tests, metrics, and documentation that dbt enables within one location.
One of the major benefits of having a centralized dbt project is the simplicity of executing models leveraging their dependencies. In a basic setup such as the following, dbt builds a directed acyclic graph (DAG) that ensures models are built in the correct order.
For example, let’s take the dbt Jaffle Shop demo. We can’t build fct_orders without stg_customers and all_orders being built/updated first (along with their dependencies); if our dependencies aren’t built/updated first, then we could be missing data, lose referential integrity (if only some tables are loaded), or introduce data lag due to a gap in processing.

Having the ability to create a DAG ensures that data flows through the models as expected and each component is only updated once its dependencies are updated. This ensures that data is consistent regardless of which model users consume.
This also gives us the ability to execute hooks or macros that affect the entire data warehouse or data modeling components in a guaranteed fashion. That is, we know when all the data modeling is complete (or has yet to start) across the organization. This allows us to do things like ensure masking policies exist, apply those masking policies in one location, or provide holistic tests against the data to ensure data quality across the entire data warehouse.
While this is ideal from an information and control perspective, as you have the ability to see how any change to the dbt project affects everything else, your organization may have rules and requirements that don’t allow this.
This could include concerns like data privacy or intellectual property. Organizations may be blending together a number of different data sources into a data product and want to keep it on a “need to know” basis.
Having a centralized dbt project also creates additional complexity for changes to be introduced to the project from a continuous integration and continuous delivery perspective. dbt projects are typically stored in a git-based repository and therefore need to follow a git-based release strategy.
There are a number of different approaches to git, but what this ultimately means is that everybody who wants to make a change to the dbt project code needs to work together to introduce changes, validate changes, decide what can be released, and decide when it can be released.
This frequently leads to one group that needs changes released as-soon-as-possible while another group has changes that cannot be released yet. This can be solved by more complicated git strategies and communication across all groups with code in the project.
Centralized projects also need to agree on things like dbt dependencies, additional packages, and project structure across all groups within the project.
Decentralized dbt Project
Within a decentralized model, dbt projects are split up into the various projects or business areas that need to perform modeling within the data warehouse. This allows each project to have a separate deployment process, git repository, git strategy, and restricts communication of releases to a smaller audience.
Each dbt project can have its own dependencies, packages, structure, and release pattern/cadence based on what makes sense to that particular audience. This setup is very common within larger enterprises.
Enterprises frequently have decentralized structures because their organization is so large that having a centralized model would be cumbersome and slow down business development. Additionally, they frequently have separate teams that work on their own priorities and therefore want to have control over their particular deadline and goals.
With a decentralized dbt project approach, the release patterns become tricky to execute as dependencies grow in the data modeling. For example, let’s take another look at the dbt Jaffle Shop DAG.
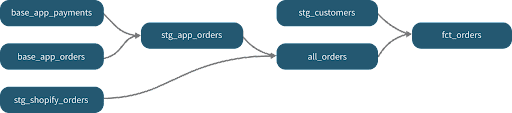
Let’s break this up into a decentralized representation of the DAG. First, we have one dbt project that has the modeling components for generating the all_orders model.

Then we have another dbt project that utilizes the all_orders data model and joins it with data from the stg_customers table to build fct_orders:

This allows for each team to make updates to their own dbt repositories and manage their own release cycle, but now we have a situation where dbt doesn’t know about the dependencies to model all_orders.
All our dbt project knows about is that fct_orders needs stg_customers and all_orders. This means we need to have the ability to determine or ensure that all_orders (in the other dbt project) have been run to load data.
We have a few different options to handle this. Let’s talk through them.
Orchestration by Time
The simplest approach to solve for multiple processes needing to run in order is spacing out the execution start time by the maximum run duration of the dependencies. This is not an ideal solution though as we don’t have guarantees that each dependency will run, execute within the expected time, or be successful in its run.
In our ongoing example, we need stg_customers and all_orders to be updated before fct_orders can be generated. We could observe all of these take at most one hour to execute and schedule them as follows:
- stg_customers: 1 AM
- all_orders: 1 AM
- fct_orders: 2 AM
In theory, since we know we have a max execution time of one hour, fct_orders should always be populated with new data on each run. However, in the real world, things happen.
Let’s say we have a service outage that causes our 1 AM run to not execute. When 2 AM comes around, we still have stale data in our dependencies. While this should eventually resolve itself (on the next execution day/time), consumers of our data may be expecting the dataset to be updated.
This solution is not recommended for production use cases but serves as an easy starting point.
Orchestration by Frequency
In a perfect world, upstream dependencies are always updated on time, without errors, and without outages. This is not the case in any system though. Service outages occur, or data for whatever reason takes longer to propagate through the system.
One approach to solving this is to run your dbt models on a more frequent cadence to reduce data lag.
Let’s go back to our timing schedule:
- stg_customers: 1 AM
- all_orders: 1 AM
We know that we have two sources of data for our model and we know that they’re updated on a particular cadence. Instead of assuming that they’ll finish in a particular time window or start at a particular time, we can instead assume that our sources will be updated “eventually” and write our transformations to handle this appropriately.
In order to do this, we need to define our models as incremental.
By defining the model as incremental, dbt will only process new data on each run. This is frequently done by utilizing a load_date column on your dataset that indicates when the record was loaded into the table.
However, we do have some additional concerns about doing this. By running our models, tests, and checks more frequently, you’re introducing additional resource utilization. If you’re leveraging the Snowflake Data Cloud for your data warehouse, this means you’ll burn additional Snowflake credits to perform the check for new data to process.
You will need to ensure you’re only processing new data and doing a full rebuild of your data model at a high frequency.
Orchestration via External Tooling
One of the most common methods of orchestration is to use an orchestration tool. Within the data engineering ecosystem, this is most frequently tools such as Airflow, Prefect, and Dagster. These tools give you the ability to define a DAG (similar to dbt) containing things like tasks, notifications, error handling, retries, integrations with external services, etc.
Generally speaking, we recommend utilizing an external orchestration tool when leveraging a decentralized dbt project.
Leveraging an orchestration tool gives us the ability to customize what we want our data pipelines to look like with dbt projects, data loading tools, data quality tools, and other various use cases.
Going back to our example, if we include our external dependencies, our data pipeline likely looks more like this:

For our sources, we have both an application database and Shopify. We are leveraging Fivetran to extract the data from these systems and load it into Snowflake. We then leverage dbt to model the data into data products on top of Snowflake.
Without an external orchestration tool, we are limited in our integration options. While Fivetran does have an integration with dbt for transformations, not every ETL tool will have this capability.
This is where we can leverage tools like Airflow to orchestrate each component for us.
We do this by building a DAG. Each task in the DAG is responsible for a component of our data pipeline from source to target and beyond. In our example, our DAG would likely look something like this:
This allows us to ensure that new data is loaded into our tables, all_orders is built and updated, and that fct_orders is updated with the new data.
While an external orchestration tool gives you the flexibility to define your DAG outside of dbt and combine tooling together, you still want to be wary of creating a monolith in this step.
You can quickly end up with one DAG that controls everything and needs to know about everything. We recommend that you categorize different areas of the business and different business functions into a group of work and have your DAG focus on solving those needs.
Leveraging Slim CI in dbt
Another functionality within dbt that you can leverage is something called Slim CI. Effectively, this allows you to use the selector state:modified+ when you build/run your dbt models. This will build only new or changed models within your dbt project and their downstream dependencies.
Please note that state comparison can only happen when there is a deferred job selected to compare state to. dbt will look at the artifacts from that job’s most recent successful run. dbt will then use those artifacts to determine the set of new and modified resources.
This allows us to run our dbt builds and runs on a regular cadence but limits execution to only the models that have new data.
The major win for utilizing Slim CI is that it can be leveraged in conjunction with other options that have been talked about thus far; you can use an external orchestration tool to kick off your Slim CI dbt jobs.
While Slim CI is possible in both dbt Cloud and OSS dbt, we recommend using this only with dbt Cloud.
Bring It All Together
One of the biggest challenges when designing any system is identifying which tools and patterns work for your organization. You may have requirements that are specific to your organization, industry, or country that you need to follow, and your tools and patterns need to enable those requirements.
The ideal system is one that gives the ability to quickly iterate on development whilst simultaneously giving you flexibility where you need it.
By leveraging an external orchestration tool, you’re able to have decentralized dbt projects while also coordinating things like data loading, notifications, error handling, retries, and other common data engineering tasks.
Need help running dbt models? Our team of data engineers are happy to assist. Reach out today to learn more about our dbt consulting services.
Common FAQ’s:
We generally recommend AIrflow or a managed Airflow solution such as Astronomer, AWS MWAA, or Google Cloud Composer. These tools allow you to bring more utility and functionality to your data pipelines and stitch together different services.
Generally speaking, it’s easier to implement a centralized approach, so start there until you have a reason to go the decentralized route. However, frequently your organization will have an opinion or reason to go one way or the other. In either approach, you should also utilize Slim CI for your dbt project.









