

Moving onto a new data warehousing solution such as Snowflake Data Cloud can be scary. You may be thinking: How are you going to get all your old data moved to Snowflake? What kinds of differences am I going to find between my old system and Snowflake? What other gotchas am I going to find as we attempt to migrate from our legacy system to Snowflake?
In this blog, we’re going to answer these questions and more. Walking you through the biggest challenges we have found when migrating our customer’s data from a legacy system to Snowflake.
Background Information on Migrating to Snowflake
So you’ve decided to move from your current data warehousing solution to Snowflake, and you want to know what challenges await you. You’re in luck because this blog is for anyone ready to move or thinking about moving to Snowflake who wants to know what’s in store for them.
Having done dozens of migrations to Snowflake for our clients, we at phData are experts in the nuances of getting a business onto Snowflake. We have the experience to know the challenges and gotchas of migrating almost any system to Snowflake.
Setting up the Information Architecture
Setting up an information architecture during migration to Snowflake poses challenges due to the need to align existing data structures, types, and sources with Snowflake’s multi-cluster, multi-tier architecture. Migrating from legacy systems often involves reconciling differences in schema designs, handling varying data formats, and addressing potential data quality issues.
Additionally, defining optimized data storage and access controls and leveraging Snowflake’s features for performance enhancements requires careful planning. Ensuring a seamless transition while accommodating business requirements, security considerations, and performance optimizations further complicates the information architecture setup during the migration process to Snowflake.
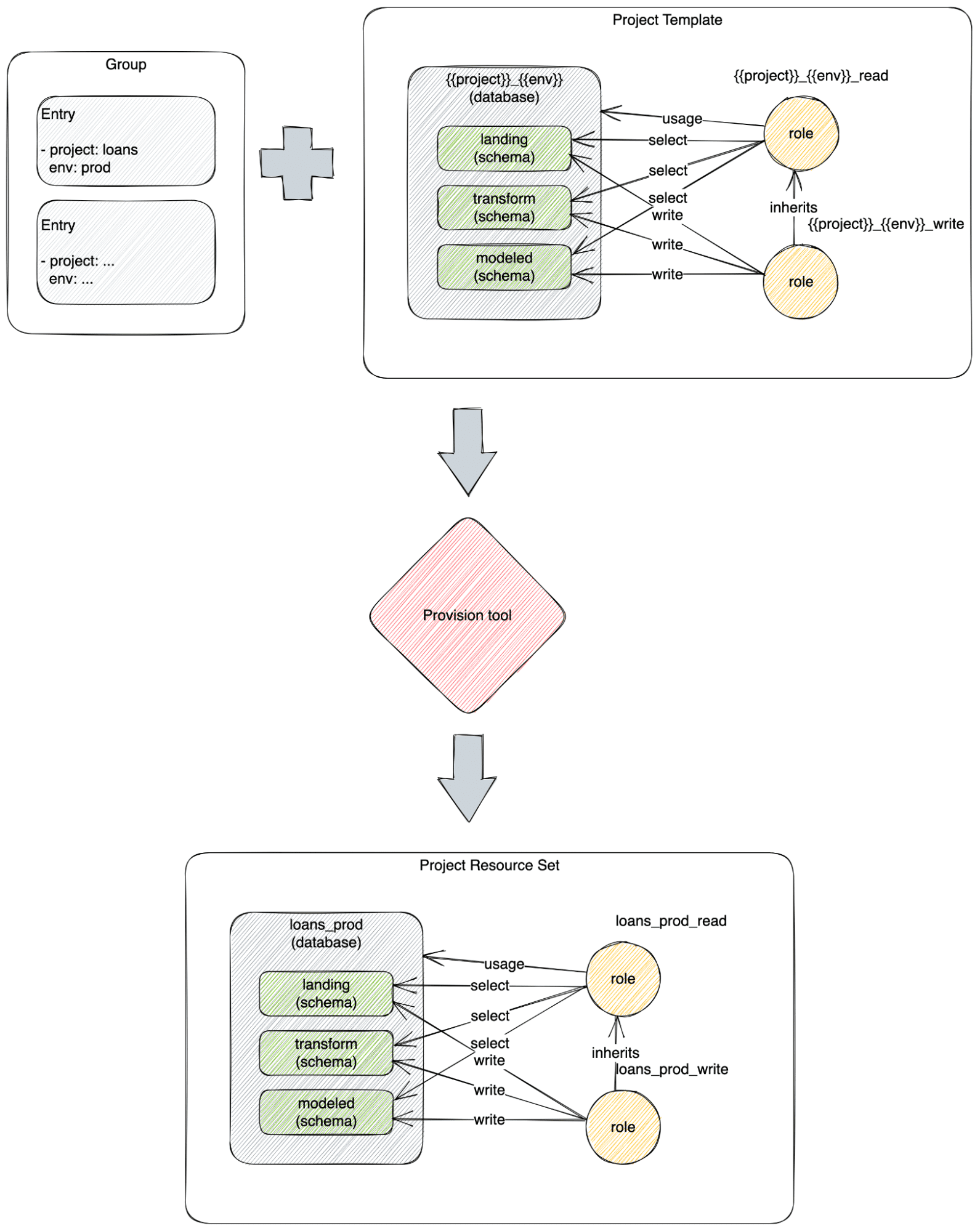
Once the information architecture is created on paper, the work of implementing it can be equally challenging. Creating the databases, schemas, roles, and access grants that comprise a data system information architecture can be time-consuming and error-prone. Luckily phData has created a template-driven Provision Tool that automates onboarding users and projects to Snowflake, allowing your data teams to start producing real value immediately.
Some of the advantages of using the Provision Tool include:
Provision faster: Scale Snowflake to thousands of users and projects easily. The ability to automatically create projects and give users the correct access to those projects decreases time-to-value.
Provision safer: Automate the process of onboarding database objects to eliminate manual work — and therefore error — while helping to ensure you’re doing it all in a controlled, governed, and consistent way, using a standard information architecture.
Provision cheaper: Save your employees valuable time by eliminating work — and it’s available for free to all phData customers. Plus, onboard your teams faster and retire your legacy platform sooner.
The tool converts the templated configuration into a set of SQL commands that are executed against the target Snowflake environment.
This diagram shows the creation of a project in the Provision tool:
Migrating Historical Data
Now that your information architecture is designed and created, you’re thinking how are you going to move all that historical data into Snowflake? Moving historical data from a legacy system to Snowflake poses several challenges.
The legacy system’s architecture, limited connectivity, and potential data quality issues can bottleneck efficient extraction, network transfer, and upload. Optimizing compression, handling resource contention, and validating large datasets add further complexity, demanding careful planning and skilled execution to ensure a smooth, error-free migration.
Moving the Data
The challenge with the actual movement of data to Snowflake from a legacy system lies in the intricacies of transitioning diverse data structures, formats, and volumes while ensuring minimal downtime and maintaining data integrity. The migration process involves extracting data from the legacy system, transforming it to align with Snowflake’s architecture, and loading it into the new environment.
Complexities arise due to differences in schema designs, data types, and storage mechanisms between the legacy system and Snowflake. Managing large datasets efficiently, optimizing for Snowflake’s cloud-based features, and addressing potential data quality issues pose considerable challenges.
Migrating Using Snowflake PUT and COPY Commands
Snowflake comes built-in with a PUT command to upload data into stages and then a COPY command that allows data movement directly from those stages into tables on Snowflake. Although moving data in this manner allows for a seamless and scalable migration, many bottlenecks can occur when taking this route:
Data Formatting and Staging:
Preparing data in the required file format (e.g., CSV, Parquet) and staging it correctly can be a manual and time-consuming process. Ensuring compatibility with Snowflake’s expectations and handling data complexities may pose challenges during this stage.
Concurrency and Parallel Loading:
While Snowflake’s COPY command supports parallel loading for efficient data transfer, optimizing this process and managing concurrency can be complex, especially when dealing with a large volume of data.
File Size and Compression:
Balancing the size of data files for optimal performance and handling compression settings can be tricky. Efficiently leveraging parallel loading while avoiding overly large or small files requires careful consideration and testing.
Error Handling and Logging:
Dealing with errors and logging mechanisms during the data movement process is crucial for troubleshooting and maintaining data integrity. Snowflake provides some error-handling features, but setting up comprehensive logging and error-recovery mechanisms may be necessary.
Third-Party Replication Tools
Third-party ingestion tools are designed for ease of use and often offer low code/no code solutions. Some tools can be used to connect to sources that native Snowflake tools cannot (without the help of API calls), such as Salesforce.
Other features include email notifications (to let you know if a job failed or is running long), job scheduling, orchestration to ensure your data gets to Snowflake when you want it, and of course, full automation of your complete data ingestion process.
There are many different third-party tools that work with Snowflake:
Fivetran
Fivetran is a tool dedicated to replicating applications, databases, events, and files into a high-performance data warehouse, such as Snowflake. The Fivetran team boasts that setup can take as little as five minutes to complete, allowing your team to move to Snowflake quickly and efficiently.
Qlik Replicate
Qlik Replicate is a data integration tool that supports a wide range of source and target endpoints with configuration and automation capabilities that can give your organization easy, high-performance access to the latest and most accurate data. Replicate can interact with a wide variety of databases, data warehouses, and data lakes (on-premise or based in the cloud).
Matillion
Matillion is a complete ETL tool that integrates with an extensive list of pre-built data source connectors, loads data into cloud data environments such as Snowflake, and then performs transformations to make data consumable by analytics tools such as Tableau and PowerBI. Matllion can replicate data from sources such as APIs, applications, relational databases, files, and NoSQL databases.
Validating the Movement
Once you begin moving the data, you need to validate that it was moved correctly. The validation process requires meticulous verification to maintain data integrity, and any discrepancies introduced during the migration are identified and rectified. Additionally, varying data quality standards, data types, and storage mechanisms between legacy systems and Snowflake further complicate the validation process, demanding comprehensive testing procedures and close attention to detail to guarantee the accuracy and reliability of the migrated data in the new Snowflake environment.
To help with this painstaking process, phData has created the Data Source tool, another free tool for our customers that automates platform migration automation. The Data Source tool discovers and compares data quality across a source and target database, so you can track the status of your migration project.
The Data Source tool can save thousands of hours in a typical large-scale migration by automating cross-data-source validations. Scans and profiles run against the entire platform (or they can be filtered down to specific databases or even tables if desired). Scans and profiles collect information about:
Entire databases
Individual tables
Each column within a table
Column data types and other metadata (like a primary key)
Column metrics like count, null count, min/max, and any other aggregation
The Data Source tool creates a visual view of the differences between the two data sources. Any difference that is found is shown in the Difference UI, where users can see if an object exists in the source only, in the target only, or is different between the two. The difference view compares all the data collected in scans and profiles:
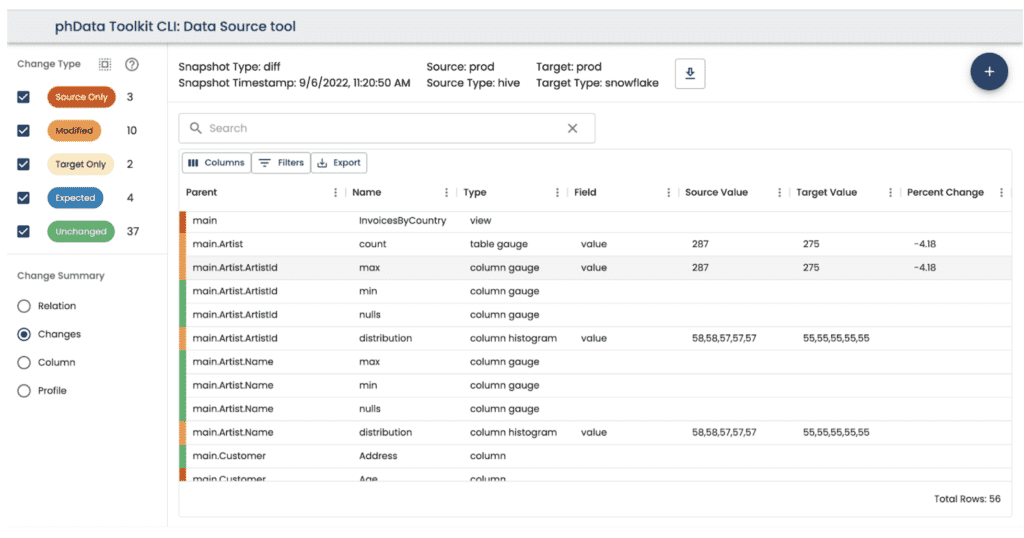
This single visual diff can replace hours and hours of manual checks and end users complaining about missing data or, in the worst case, making a decision based on bad data.
Migrating Your Pipelines and Code
It’s more than likely that your business has years of code being used in its data pipelines. Manually converting this code to work in Snowflake can be very challenging with differences in data processing paradigms, query languages, and overall system architecture.
Many legacy systems use their own languages, such as Netezza’s netezzaSQL or Teradata’s TeradataSQL, requiring significant effort to rewrite and adapt code for compatibility with Snowflake. Ensuring a seamless transition also involves adjusting to the nuances of Snowflake’s performance optimization mechanisms.
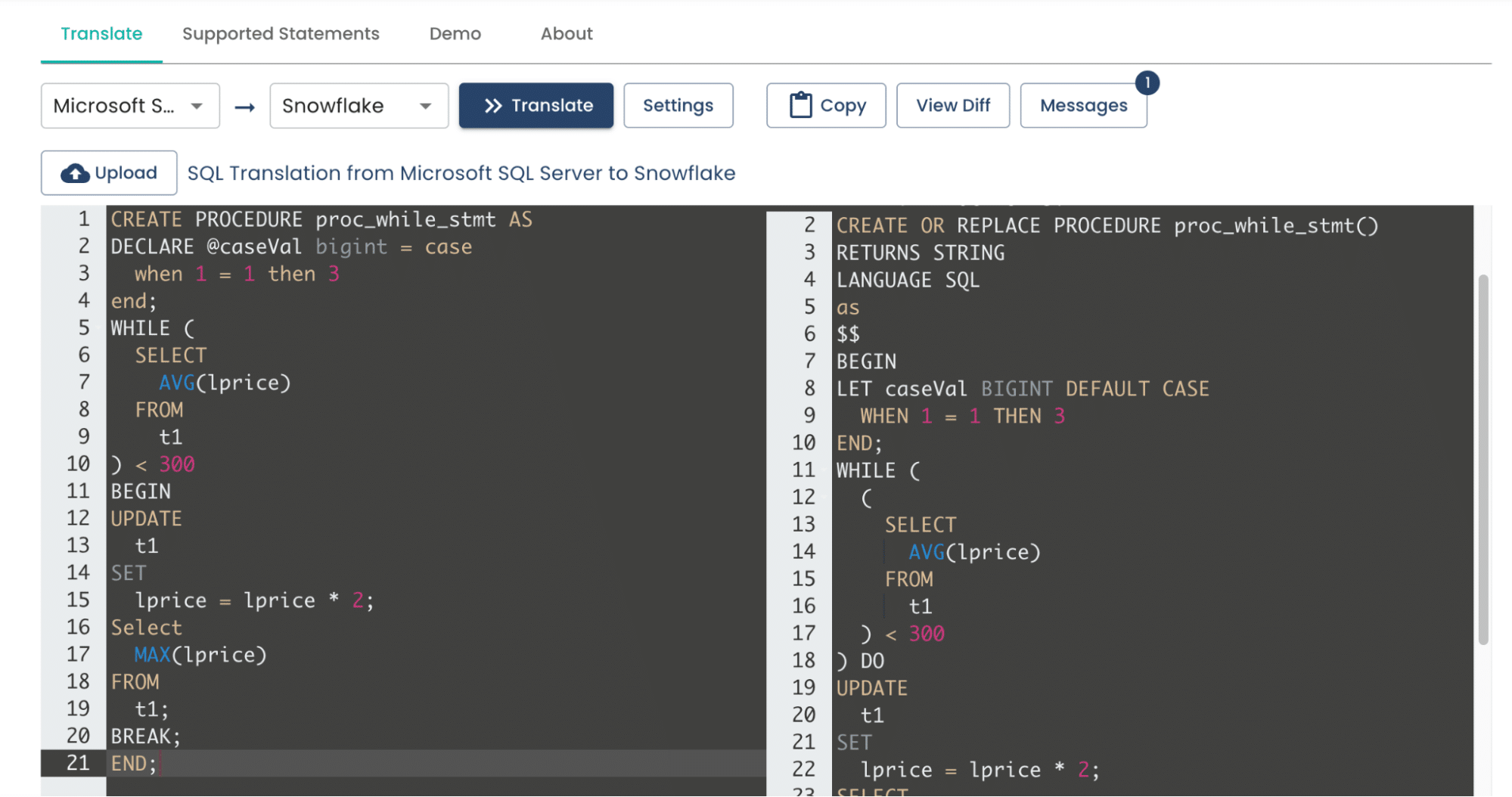
Instead of manually converting these queries, consider using software built to automate the translation of queries from your legacy systems language to Snowflake’s version, such as phData’s SQL Translation Tool.
The SQL translation application instantly converts queries from one SQL dialect to another. Essentially, it functions like Google Translate — but for SQL dialects. Automated translation is especially indispensable when migrating between data platforms but can help save time and minimize errors whenever you need to translate SQL from one dialect to another.
It is also a helpful tool for learning a new SQL dialect. Users can write queries they are familiar with and use the translation result to learn the equivalent syntax.
The application can perform complex transformations as a true transpiler or source-to-source compiler that many simpler regular-expression-based tools cannot. The result is more accurate translations and valid output, even for the most complex translations.
Best Practices for Any Migration to Snowflake
Plan everything before you start
Make a migration checklist of everything that needs to be done
Take an inventory of every object you’re going to move
Determine your approach of Lift and Shift vs. Restructuring
User training and communication
Provide comprehensive training to users on the new Snowflake environment. Communicate changes, address concerns, and ensure that users are familiar with the tools and features available in Snowflake.
Read as much about your particular migration as you can
Someone, somewhere, has done a similar migration from your legacy system to Snowflake and has written a blog about it, possibly even many someones. Read them all. Get to know all the ins and outs of your upcoming migration. Here are just a couple that phData has written that could help you along in your migration:
Need more tips on how to better plan for your migration? We have you covered!
Closing
Migrating to a new data warehousing platform can be a challenging endeavor. After reading this blog, you should better understand what can come your way when you’re moving onto Snowflake and what you can do to make your migration run smoothly.
At phData, we specialize in creating customized migration paths to help businesses transition from other database platforms to Snowflake. Our goal is to assist with cloud adoption challenges and optimize operational capabilities while focusing on cost management and scalability.
To help achieve this goal, we offer a complimentary Snowflake Migration Assessment Workshop, where we put our expertise to the test to help your organization:
Select the right combination of approaches for your migration to Snowflake
Assess your current technology and make recommendations
Estimate how long your Snowflake migration project will take
Identify key technology partners that can help streamline the migration
Answer any migration questions you have
FAQs
Organizations can address security concerns while migrating sensitive data to Snowflake by employing encryption at rest and in transit, enforcing multi-factor authentication and granular access controls, establishing private network connections, implementing security monitoring and logging, and prioritizing data minimization, governance, and personnel training. Security is a continuous journey, so seek expert advice to tailor your approach.
To minimize downtime and maintain business continuity during Snowflake migration, organizations can leverage strategies like phased migration, utilizing data pipelines for continuous syncing, employing tools for near-zero downtime cutover, and proactively testing backups and disaster recovery plans. Careful planning, robust communication, and thorough testing throughout the process are key to a seamless and successful transition.









