Kudu is an excellent storage choice for many data science use cases that involve streaming, predictive modeling, and time series analysis. However, in industries like healthcare and finance where data security compliance is a hard requirement, some people worry about storing sensitive data (e.g. PHI, PII, PCI, et al) on Kudu without fine-grained authorization.
Kudu authorization is coarse-grained (meaning all or nothing access) prior to CDH 6.3. (CDH 6.3 has been released on August 2019). Because of the lack of fine-grained authorization in Kudu in pre-CDH 6.3 clusters, we suggest disabling direct access to Kudu to avoid security concerns and provide our clients with an interim solution to query Kudu tables via Impala.
In this post, we will be discussing a recommended approach for data scientists to query Kudu tables when Kudu direct access is disabled and providing sample PySpark program using an Impala JDBC connection with Kerberos and SSL in Cloudera Data Science Workbench (CSDW).
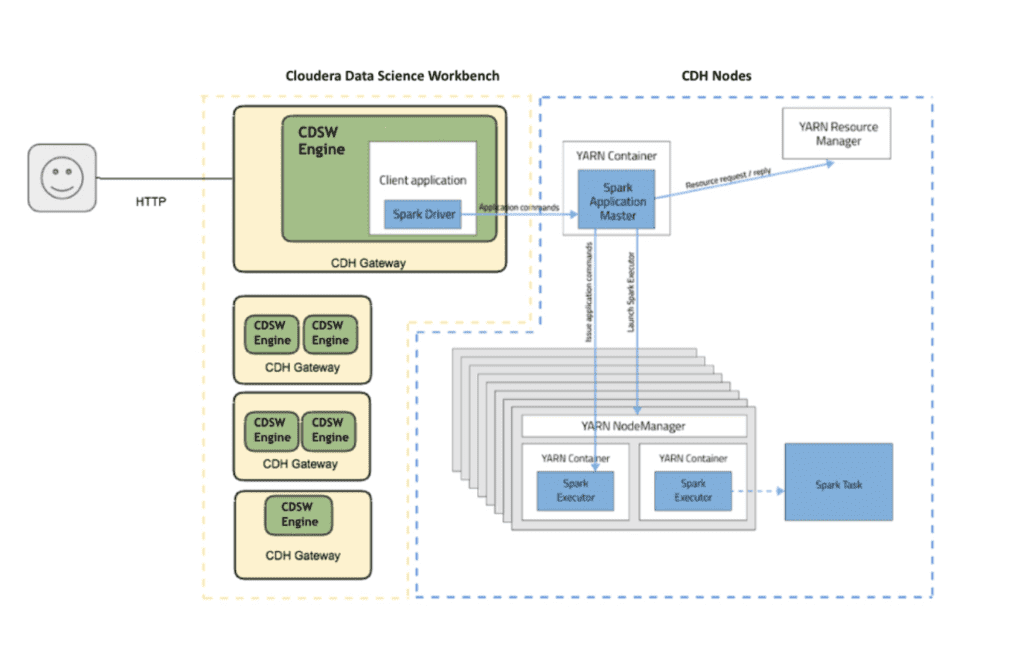
Cloudera Data Science Workbench (CDSW) and Spark Architecture
Cloudera Data Science Workbench (CSDW) is Cloudera’s enterprise data science platform that provides self-service capabilities to data scientists for creating data pipelines and performing machine learning by connecting to a Kerberized CDH cluster. More information about CDSW can be found here.
Spark is the open-source, distributed processing engine used for big data workloads in CDH. CDSW works with Spark only in YARN client mode, which is the default. In client mode, the driver runs on a CDSW node that is outside the YARN cluster.
Different Ways to Query Non-Kudu Impala Tables in CDSW
There are several different ways to query non-Kudu Impala tables in Cloudera Data Science Workbench. Some of the proven approaches that our data engineering team has used with our customers include:
- Using Spark/Spark SQL
This is the recommended option when working with larger (GBs range) datasets.
This is a preferred option for many data scientists and works pretty well when working with smaller datasets.
- Using Impala ODBC Drivers
This option works well with smaller data sets as well and it requires platform admins to configure Impala ODBC.
- Using Spark with Impala JDBC Drivers
This option works well with larger data sets.
How to query a Kudu table using Impala in CDSW
When it comes to querying Kudu tables when Kudu direct access is disabled, we recommend the 4th approach: using Spark with Impala JDBC Drivers. We will demonstrate this with a sample PySpark project in CDSW. As a pre-requisite, we will install the Impala JDBC driver in CDSW and make sure the driver jar file and the dependencies are accessible in the CDSW session.
Step 1
First, we create a new Python project in CDSW and click on Open Workbench to launch a Python 2 or 3 session, depending on the environment configuration.


Step 2
We generate a keytab file called user.keytab for the user using the ktutil command by clicking on the Terminal Access in the CDSW session.
Step 3
We create a new Python file that connects to Impala using Kerberos and SSL and queries an existing Kudu table.

Step 4
JAAS enables us to specify a login context for the Kerberos authentication when accessing Impala. In this step, we create a jaas.conf file where we refer to the keytab file (user.keytab) we created in the second step as well as the keytab principal.

Step 5
We also specify the jaas.conf and the keytab file from Step 2 and 4 and add other Spark configuration options including the path for the Impala JDBC driver in spark-defaults.conf file as below:

Adding the jaas.conf and keytab files in ‘spark.files’ configuration option enables Spark to distribute these files to the Spark executors.
Step 6
Finally, when we start a new session and run the python code, we can see the records in the Kudu table in the interactive CDSW Console.

Conclusion
Without fine-grained authorization in Kudu prior to CDH 6.3, disabling direct Kudu access and accessing Kudu tables using Impala JDBC is a good compromise until a CDH 6.3 upgrade. Like many Cloudera customers and partners, we are looking forward to the Kudu fine-grained authorization and integration with Hive metastore in CDH 6.3. If you want to learn more about Kudu or CDSW, let’s chat!


