

phData is excited to release the Data Generation Tool, a relational synthetic data generator tool, from the phData Toolkit.
Every dataset has a story rooted in the relationships and patterns among its columns, enabling analysts and engineers to uncover valuable insights. However, traditional data generation tools fail to capture these complex dynamics that give real meaning. This is where our Data Generation Tool shines.
What is the Data Generation Tool?
The Data Generation Tool creates ultra-realistic-looking synthetic relational data for analytics, data engineering, and AI use cases. It was designed to allow engineers to jump-start their projects by using synthetic data before real data is available or to test new scenarios with data that doesn’t exist yet.
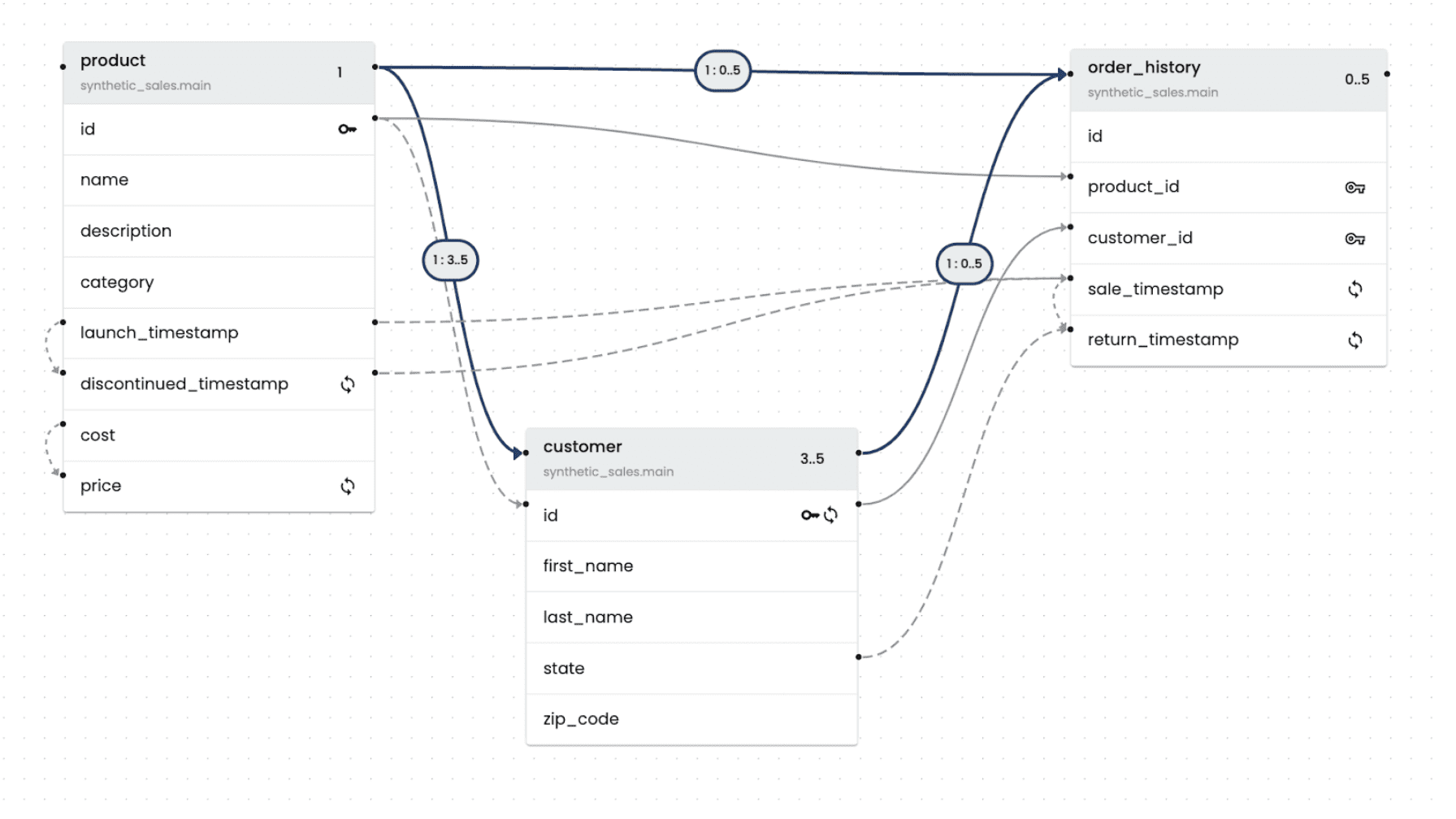
To create synthetic relational data that can tell convincing stories, we built a new type of data generation tool that preserves the constraints, relationships, and correlations of real data.
Using this realistic synthetic data, users can:
- Enable development or create a POC before the real data is available.
- Create realistic performance-testing environments.
- Create detailed, true-to-life analytics dashboards.
- Test data pipelines without needing access to sensitive data.
- Test specific scenarios in data pipelines (like error handling or outlier detection).
What Types of Data Does the Data Generation Tool Create?
The Data Generation Tool provides new ways to create data that closely matches the properties and characteristics of real data, including:
Comprehensive Provider Library
Offers a wide range of data providers for creating realistic names, PPI, location data, and more, ensuring columns are filled with convincing data.
Adherence to Real Constraints
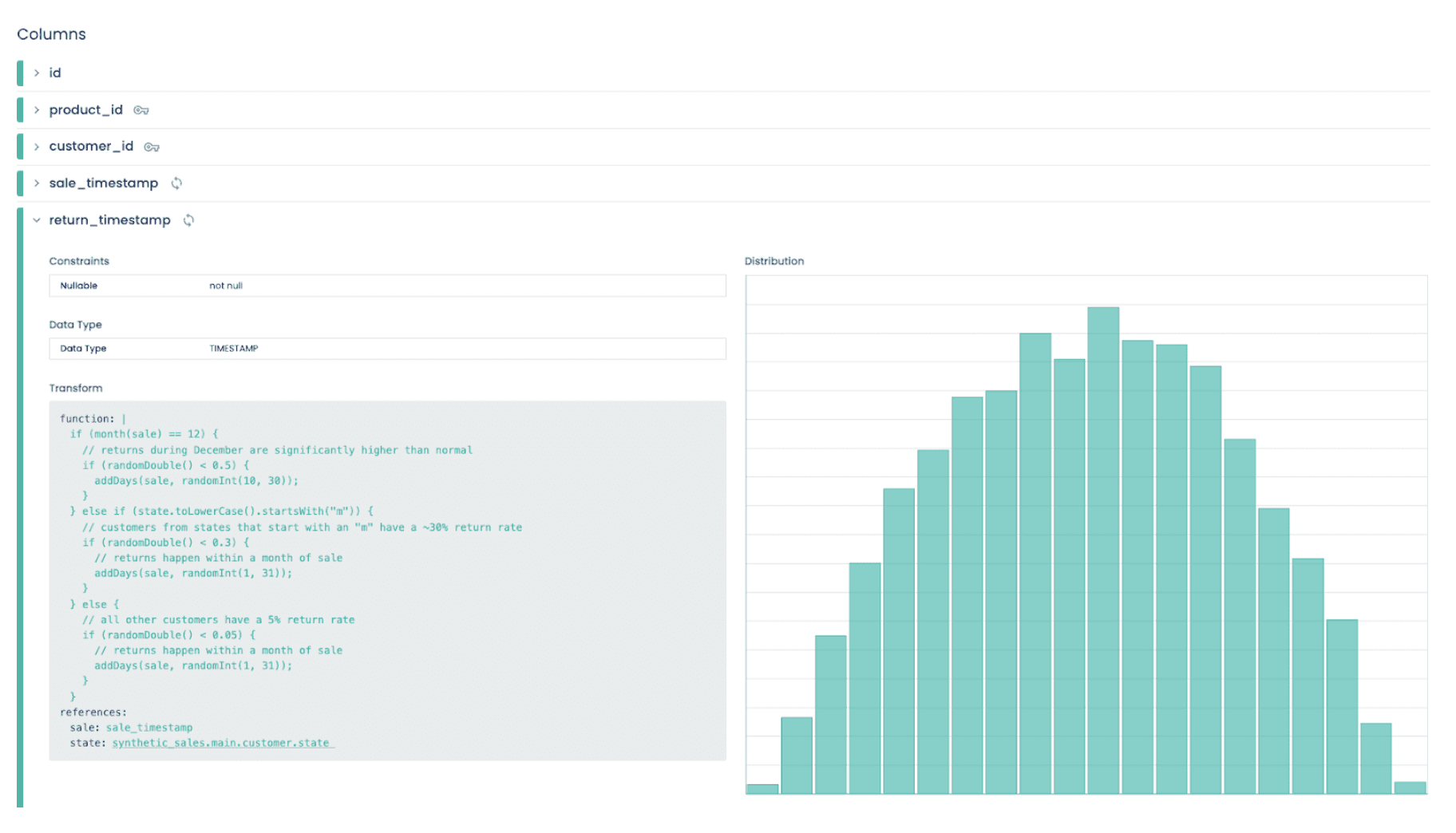
Recognizes and maintains real data constraints, such as uniqueness, non-null, or primary keys. For example, if a column is numeric and unique, the generated data will mirror these traits.
Joinable Data
Produces synthetic data that preserves the primary/foreign key relationships of real data, while maintaining one-to-many or many-to-one relationships.
Realistic Distributions
Generates data with various distributions, including normal or skewed, to ensure analytic dashboards are accurate and visually appealing from the outset.
Modeled Correlations
Maintains correlations between data columns (whether linear, exponential, or any other type of relationship), ensuring synthetic data closely mimics the real world.
Schema-scanning Capability
The Data Generation Tool can scan your existing schema, whether a single table or 100, and extract the relationships and constraints. It can then automatically generate and insert realistic synthetic data.
Learn More About the Data Generation Tool
Use the following links to learn more about the Data Generation Tool and how phData can help speed up the development of your data products:










