Simplifying Semi-Structured Data Analysis With Alteryx & Snowflake
By Thales Donizeti
Semi-structured data, such as JSON-formatted data, has become increasingly prevalent in today’s data-driven world. JSON is particularly common as it is widely used in web APIs for sending and receiving data.
JSON is a lightweight and flexible data format that allows easy communication between applications and systems. Additionally, JSON data is often used to store complex data structures, such as hierarchical data, making it an ideal format for handling semi-structured data.
However, working with semi-structured data like JSON can present unique challenges regarding analysis. Unlike traditional structured data, semi-structured data lacks a formal schema, making it more flexible but also more difficult to work with.
Fortunately, platforms like Alteryx and the Snowflake Data Cloud can help simplify working with semi-structured data. Alteryx provides powerful features, such as its JSON Parser, which can help analyze VARIANT data type fields from Snowflake. This versatile data type can store semi-structured data, allowing for flexibility in handling various data formats within a single column.
Meanwhile, Snowflake SQL Syntax can be used to explode VARIANT fields in Alteryx, allowing for easier analysis. When used together, Alteryx and Snowflake make an excellent combo for dealing with semi-structured data.
In this post, we’ll explore how to leverage these platforms to make your analytics faster and more powerful, using examples to illustrate their potential.
How Can Alteryx Load JSON Data to Snowflake?
Loading JSON data from Alteryx to Snowflake is a seamless process with the right configuration. To illustrate, let’s take the Alteryx Server API response as an example.
When using Alteryx Designer, you can fetch workflow metadata from the Alteryx Server using its API, and this data is typically returned in JSON format. Our objective here is to store the original API response in Snowflake, ensuring that we retain the data for auditing purposes.
Let’s dive into the process:
Workflow that captures data from the Alteryx Server API
The download data is originally a string field in Alteryx, but we will figure out a way to store it as a VARIANT field in Snowflake. To start, add an Output Data tool and utilize a Bulk Load connection to Snowflake to perform the loading (it’s the fastest and most optimal way to load data).
Outputting Alteryx Server API data to Snowflake
Pro Tip: When loading data into Snowflake, it’s a smart move to include an Auto-Field tool and a Select tool in your workflow. These tools help you verify and align the data type sizes before the final output. Remember, Snowflake has its own distinct size limitations that may differ from those in Alteryx.
You can utilize Pre-SQL and Post-SQL statements to convert STRING to VARIANT when using the Bulk Loader in Snowflake. By selecting the “Delete Data & Append” Output option, you can implement this technique.
In the Pre-SQL statement, create a temporary table to store the JSON data as a string. Then, in the Post-SQL statement, create the final table by selecting from the temporary table and applying the conversion to JSON using the PARSE_JSON SQL function.
After processing, the temporary table is purged, leaving you with a new table that includes a VARIANT column for the converted data.
Pre-SQL statement
Post-SQL statement
Pro-Tip: Before running these scripts, ensure that you have already created the necessary parent objects, such as the Database and Schema, in Snowflake. Having these in place is crucial to avoid errors during execution. Additionally, double-check that the role specified in your ODBC connection has the necessary privileges to CREATE tables. This ensures a smooth and successful execution of the scripts without any authorization issues.
Table description confirms the VARIANT data type in Snowflake
Another approach, which is even simpler and doesn’t require any SQL statements, is to utilize In-Database tools. With this method, you can create a temporary table and leverage the Formula In-DB tool to apply the PARSE_JSON function.
Once the transformation is applied, you can output the data to the appropriate final table. It’s worth noting that you can leave the Field type as V_WString in the Formula In-DB tool.
Snowflake will automatically recognize and interpret it as a VARIANT data type, simplifying this process. This approach offers a straightforward and efficient way to handle the conversion without additional SQL statements.
Simple workflow to output JSON data as a VARIANT data type in Snowflake
Analyzing JSON Data with Snowflake SQL
In Snowflake, there are various techniques available for working with JSON data, and one of them involves employing the FLATTEN function. By utilizing the FLATTEN function in conjunction with the LATERAL keyword, you can transform your nested JSON structure into a tabular format.
This approach allows you to expand the values within your JSON object as individual columns, making exploring and analyzing the data simpler.
LATERAL FLATTEN query to explode JSON fields into columns and rows
Pro-Tip: You can also run this query directly in Alteryx using the Input Data tool or the Connect In-DB tool. This allows you to bring the table into your workflow for further investigation.
Using the FLATTEN function in the Input Data tool
Analyzing JSON Data with Alteryx Tools
Alteryx offers a suite of tools designed to simplify the parsing of JSON data into a tabular format. To begin, you can utilize the JSON Parse tool, which breaks down the JSON structure into rows. Each element within the structure will be assigned a numerical prefix followed by a dot (e.g., “0.”, “1.”, “2.”, and so on). This parsing process allows for easy extraction and manipulation of the JSON data.
JSON Parse tool configuration and output
To split the “JSON_Name” column into two, we can use the Text to Columns tool in Alteryx with the dot (.) as the delimiter. This action creates two columns: one for the element number and another for the desired column name.
Text to Columns configuration and output
After splitting the JSON_Name column, two additional columns will be generated: “JSON_Name1” and “JSON_Name2”.
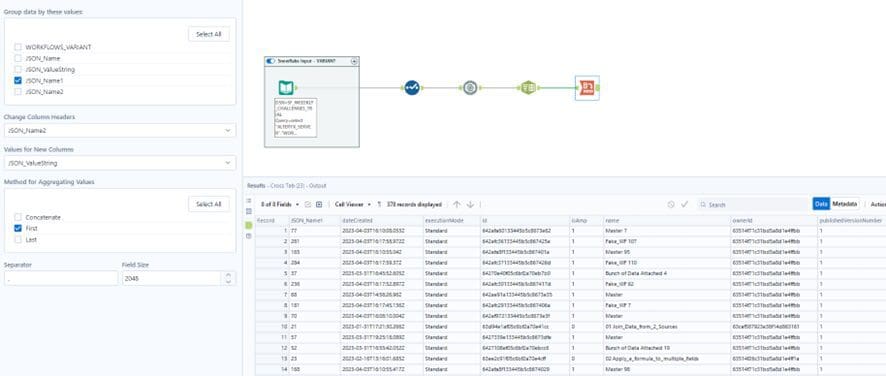
To shape the data, we can pivot it using the Cross Tab tool. By grouping the data based on the “JSON_Name1” column (element number), we can utilize the “JSON_Name2” column as the Column Header and the “JSON_ValueString” as the Value for the new columns.
The specific method for aggregating values is irrelevant at this stage, as each element will be associated with a single column and value. Feel free to choose the “First” option for aggregation.
Cross Tab tool configuration and output
At this stage, you can sort the data based on the element number (“JSON_Name1”) and exclude this column from your final output. And there you have it – your JSON data presented in a table format!
Final output for the JSON data in a table format
In this example, the JSON structure is not deeply nested. However, for more complex JSON structures, additional steps may be necessary while following the same logic. The key is to utilize these tools to navigate through the JSON levels until you reach a table format that can be better comprehended for analysis.
Conclusion
If you use Alteryx or Snowflake for this task, you have ample resources and techniques at your disposal to simplify the process of transforming this data into a human-readable format. The combination of Alteryx’s powerful tools, such as the JSON Parse, and Snowflake’s capabilities for handling semi-structured data, including the VARIANT data type, provides a robust framework for efficient data analysis.
If you find yourself needing assistance with your analysis or aiming to unlock the full potential of your data, phData’s expertise in Alteryx and Snowflake can help you navigate the intricacies of working with semi-structured data, streamline your workflows, and extract valuable insights.
Don’t hesitate to reach out to us for personalized guidance and support in maximizing the value of your data.