
Top US Truckload Carrier Simplifies On-Prem Data Migrations to Snowflake and HVR
Customer's Challenge
A leading U.S. trucking company sought to leverage up-to-date operational data and insights to improve decision-making across the organization. However, the data was stored in legacy on-premise IBM DB2 and SQL Server systems, which were historically challenging to access and use for large-scale data analysis. To truly build a best-in-class, modern data analytics platform, they needed to migrate to the cloud and unlock their data’s potential.
phData's Solution
Through a data strategy engagement with phData, the client intended to align their business needs with their future data platform. The organization landed on using Fivetran HVR (High Volume Replicator) for their migration as it provided a centralized, flexible, and scalable solution to their data migration needs. After assisting in the setup and initial configuration of HVR for the organization, phData’s delivery team collaborated with the client’s administrators to accelerate the migration of several hundred tables to the Snowflake Data Cloud.
Results
- Installed agents to all identified SQL Server Systems and set up channels for replication (5 databases).
- Setup an on-premise PROD and QA HVR hub.
- Migrated 30+ tables from a highly transactional SQL Server database.
- Migrated 200+ tables from a large DB2 database.
This migration effort and the layer of raw data that it created within Snowflake were then used as the backbone to begin re-platforming and centralizing the legacy data warehouses that existed on-prem.
It also opened the opportunity to continue to innovate on top of those existing warehouses. Now that HVR had simplified the pattern and work necessary to move data, it allowed the engineering team to focus on producing valuable data assets instead of simply maintaining infrastructure.
The Full Story
The client had invested months earlier in their cloud-based data warehousing solution, Snowflake. Unfortunately, momentum had stalled on the migration of data into Snowflake for a few reasons:
First, the organization desired to avoid its previous mistake of using a polyglot of data integration tools which required significant effort whenever changes were necessary, and maintenance was required. Instead, they wanted to create a single, consistent pattern for replicating data into a new centralized platform.
Second, they wanted to accelerate their ability to change and adapt to evolving requirements. The organization was immature in its data strategy and thus understood that there would be changes along the way to maturing that strategy.
Third, they wanted to adopt good architectural principles when setting up their replication components, balancing the trade-offs of agent-based replication, CDC replication methodologies, installing components on-prem vs. in the cloud, and the use of compression and encryption.

Why phData?
phData was initially introduced to the client via a strategy engagement as they sought guidance during their transition to Snowflake. Because of the knowledge and experience the phData team had in accelerating migrations to Snowflake using Fivetran HVR, the client requested involvement from phData again to ensure a smooth transition. The client recognized phData as a reliable partner and trusted them to help drive momentum in this project.
Architecting & Setting Up HVR
The phData team invested time and effort to understand and address the client’s requirements, including performance, data encryption, and easy integration with the required databases.
Fivetran’s HVR product, which had the performance advantages of on-prem log-based replication and native connectors for DB2 and SQL Server, was identified. phData used their experience to help guide the client’s team through choosing the best way to implement HVR’s flexible architecture to meet those requirements.
Below are highlights of the architecture for each system:
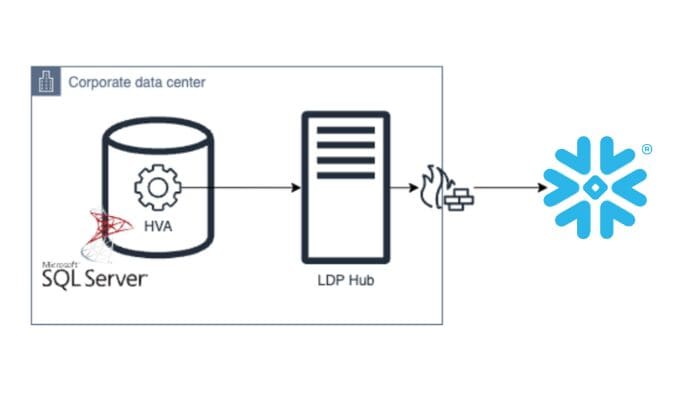
SQL Server
- High Volume Agent (HVA) was installed on the database server to enable log-based CDC.
- HVR (previously known as LDP) Hub was installed internally to the corporate data network to reduce data traffic outside of the corporate network and simplify network communication.
DB2 (iSeries)
- Only an ODBC connection is supported by HVR for iSeries DB2; thus, no HVA was installed on the database server.
- The same HVR Hub for the SQL Server was used, but the HVA was installed directly on the Hub server to offload CPU cycles from the Hub process.

Each system came with its own set of challenges. For example, one SQL Server source was a third-party database installed and managed by the client’s DBA team. This system had strict access and performance policies and was historically sensitive to changes. However, upon deploying and testing the performance of the system’s end users while running HVR replication, there was little noticeable impact.
Navigating Changes in the Project
During the project, there were changes in leadership at the client’s organization as well as a changed focus on the business goals. Maintaining momentum despite these changes was crucial, and the phData team successfully made progress and adapted to the shifting direction.
One reason for this success was that phData emphasized automating the infrastructure around the HVR system.
Although HVR itself continued to be a manual configuration, the onboarding process for new sources in Snowflake was scripted via a configuration in the Provision Tool (phData’s free tool that automates the onboarding of users and projects to Snowflake). This enabled consistent forward motion while allowing flexibility to shift directions at any time as business changes were made.
Take the next step
with phData.
Looking into better data options for your organization? Learn how phData can help solve your most challenging problems.





