

GenAI lowers the cost of generating ideas, content, and code, but the capacity to distinguish signal from noise is scarce.
To tackle the signal-versus-noise problem, this deep dive covers three things:
How GenAI productivity works and which bottlenecks keep clever demos from becoming real-world value.
How new skills, roles, and workflows turn GenAI outputs into scalable, better products.
What’s next, via a simulation-backed guide to prototyping, tracking, and evaluating GenAI applications.
Readers will leave ready to convert GenAI proofs of concept into measurable gains, unlock bottlenecks, and pull strategic levers to advance their company.
Why GenAI?
For perspective, consider this metric: with LLMs, a single contributor can now match the output of two people. And teams are three times more likely to reach standout decisions.
Now scale that lift across entire sectors (not just a few first movers) and the rules of law, education, and politics begin to realign.
But even when the tech exists, change takes time, and updating institutions, incentives, and social norms takes far longer.
That lag also shows up inside companies: early adopters are already capturing double-digit productivity gains from GenAI, but the vast majority of firms remain stuck.
U.S. firms’ GenAI roll-outs have doubled, yet 75% still can’t scale their proofs of concept due to a lack of expertise.
Even when that talent gap is closed, progress can still stall when team members hesitate to rethink entrenched routines.
At the opposite extreme, Big Tech fuels CapEx at historic levels, funding data centers, models, and chips, gatekeeping future productivity gains, and leaving typical firms behind.
Simultaneously, all that spending and decades of research have created a new division of labor.
Models will handle the groundwork, humans will frame directions, run experiments, and assess outcomes.
The puzzle is no longer whether GenAI matters, but who can harness it—and how.
How GenAI’s Value Stays Hidden
You can see the computer age everywhere but in the productivity statistics.
Robert Solow
ChatGPT rocketed to mass adoption, and GenAI is a revolution, so why doesn’t GDP show it?
The answer begins with the Solow Paradox, which attributes the productivity gap to inputs GDP misses—software, data, training, and organizational redesign.
That blind spot creates a productivity J-curve: output dips while firms build those hidden assets; only when these assets mature does productivity snap back and rise.
GenAI matches the pattern: the models can write code, draft phD-level literature reviews, and uncover new scientific leads.
However, returns materialize only when daily work is tuned to harness GenAI fully.
In addition, most AI-GDP studies end in 2017, capturing the rise in intangible investment but missing the post-2018 GenAI wave, so they show no productivity rebound.
Since OpenAI released its first LLM in 2018, rapid model improvements have outpaced organizational adaptation.
Daron Acemoglu expects only a 0.06 point annual productivity lift, while Alex Tabarok says the payoff could be much larger if GenAI also delivers on three fronts:
Generate jobs that outweigh harmful uses
Accelerate scientific discovery
Drive deeper automation in today’s software, robots, and factories
When GenAI reaches critical mass across jobs, science, and automation, the economy will scale the J-curve’s steep rise, rewarding pioneers and imposing costly catch-up on late adopters.
Which Bottlenecks Undermine Productivity
We must take seriously the economic opportunities presented by the potential for producing new ideas.
Paul Romer
Romer formalised the proverb “standing on the shoulders of giants”, showing that cumulative ideas fuel economic growth.
His theory rests on the fact that knowledge behaves differently from ordinary capital:
Knowledge is non-rival: When one person uses an idea, everyone else can use it at zero extra cost.
Knowledge compounds: Each discovery enlarges the shared commons of ideas, expanding the public knowledge base for the next growth wave.
GenAI now accelerates both properties. As ideas proliferate faster than experts can scrutinise them, unverified knowledge competes for limited attention.
Phase |
Canonical View |
Technological Shift |
Emergent Scarcity |
|---|---|---|---|
Generation |
Costly R&D; new ideas drive growth |
LLMs cut the cost of drafts |
Need for high-quality filters |
Evaluation |
Validation bundled into R&D |
Framing and testing remain expert-intensive |
Evaluator capacity |
Rivalry |
Ideas are non-rival; capital and labour are rival |
Raw ideation is plentiful |
Experimentation culture |
Takeaway: Scarcity now lies in evaluation, not generation.
GenAI has turned a once-rare flow of ideas—and code—into abundance, making expert bandwidth the binding constraint.
Therefore, leadership should redesign how every task is done, embedding evaluation checkpoints that quantify the impact of reimagined work.
In parallel, employees need the freedom to experiment, and R&D must sprint through rapid build–test–iterate cycles.
This new reality raises tough questions:
Organizational know-how. Are processes innovation-friendly? Are roles like GenAI Engineer and Chief GenAI Officer established?
Workforce skills. Do teams have sufficient training and dedicated time for trial and error with new tools? Are employees being heard on how GenAI can be useful?
Culture & leadership. Is leadership implementing a GenAI strategy? Is that strategy being undermined by risk-averse managers, skeptical employees, or short-term targets?
Why Skills of the Future Are Product-First
Chip Huyen’s newest book distills the generative-AI stack into three layers:
Layer |
Purpose |
Expertise leveraged |
Core tasks |
|---|---|---|---|
Application Development |
Uses existing models to build products |
Product-oriented mindset |
Interface design; Prompt engineering; Context construction; Evaluation |
Model Development |
Creates foundation models |
Traditional Data Science |
Dataset engineering; Model training; Fine-tuning; inference optimisation; Evaluation |
Infrastructure |
Provides the runtime backbone for models and apps |
MLOps & Data Engineering |
Model & app serving; Data-and-compute management; Monitoring |
Huyen outlines the following priority flip between ML and AI engineering:
ML Engineering: Data → Model → Product
AI Engineering: Product → Data → Model
Breakthroughs like the Nobel-winning transformer that predicts protein structures keep coming on the classic ML model front.
However, the greatest opportunities lie in the application layer.
Moving from model-first to product-first favours agile, GenAI-focused teams, allowing them to build better products.
Data-mesh principles are one way to translate this product-first stance into executable blueprints:
Evaluation capacity (EC) — A unified observability-and-metrics platform that helps teams triage ideas, trace results, and rank experiments. A cross-functional board, backed by redesigned governance, uses the platform’s insights to prioritise high-value problems, create OKRs, set standards, and steer resources.
Experimentation culture (ExC) — Autonomous, product-centric squads apply design thinking and lean build–measure–learn loops to test, prototype, launch, and market products.
Each squad pairs a GenAI engineer with a domain expert and taps the shared observability platform for curated data, rapid prototyping, continuous deployment, and feedback.
Squads own the full cycle, from framing hypotheses to prototyping, gathering feedback, iterating startup-style to product-market fit, and ultimately scaling the winners.
Together, evaluation and experimentation move coding from hand-tooled scripts to continuous, GenAI-reinvented programming and updated team design.
In turn, the same will happen in data engineering.
Autonomous agents will re-architect the data lifecycle, from data modelling and infrastructure-as-code to platform migrations, CI/CD, governance, and ETL pipelines.
What's Next: Economics of Experiments & Evaluation
Forward-thinking firms invest in continuous training, foster a product mindset, and field decentralized dev squads paired with domain experts.
They also re-examine middle-management roles and core processes through a GenAI lens, grounding everything in data-engineering fundamentals, classic ML, and agile governance.
With these foundations in place, unlocking value in unstructured data becomes easier.
That new approach demands talent.
While start-ups can tune everything natively for GenAI, established firms attract creative, experiment-minded engineers by offering what start-ups cannot: stability and scale.
Ultimately, these elements converge on a shared prototyping-and-observability platform, turning evaluation capacity and an experimentation culture into a growth engine.
To stress-test this GenAI playbook, nearly 1,000 micro-economic simulations (≈30M data points) were run, revealing three patterns.
The results echo the bottlenecks traced—capital timing, R&D mix, evaluation throughput, and knowledge flows.
Pattern 1 — Boom-and-Bust vs. Steady Investment
Two capital-allocation styles in GenAI were tested: an early-peak “big-bang” spend followed by retrenchment, versus a steady, compounding outlay.
Boom-and-bust spending works only when the payoff window is predictable: If a GenAI breakthrough is clearly timed and the firm already holds the needed intangibles, one bold up-front outlay can lock in a lasting advantage.
Steady investment pays off over a long horizon: Capital, talent, and capabilities grow together as automation unfolds gradually and predictably, being more resistant to crisis.
Pattern 2 — Production vs. R&D
Balancing exploration (research) and exploitation (delivery) determines how quickly and how long GenAI returns accrue.
Dynamic strategy is better: Firms that continually tune the production and R&D mix stay ahead and beat static plans.
If you start R&D-first: Pivot to production once a viable innovation is ready, especially when market disruption or first-mover advantage looms.
If you start production-first: Keep a baseline R&D budget and ramp discovery before growth plateaus, using early revenue to fund the next sprint.
Pattern 3 — Evaluation Triage
How GenAI outputs are screened, tested, and promoted determines whether related projects accelerate or stall.
Balanced Screening: Objective rules that aren’t overly rigid for judging GenAI ideas prevent innovation stagnation and overwhelming backlogs.
Vertical Edge, Horizontal Scale: Tailor GenAI to your vertical’s edge first, then scale proven wins to broader domains like finance and marketing.
Blend perspectives: Panels that pair generalists (breadth for navigating uncertainty) with specialists (depth for technical quality) deliver better reviews.
Move fast and don’t break things: Rapidly approve, build, and test to counter idea decay and rival copycats, but apply due diligence to avoid premature launch pitfalls.
Conclusion
If you found this blog’s ideas and content interesting and would like to continue the conversation, feel free to contact me on LinkedIn.

Free GenAI Workshop
Additionally, we’re hosting a series of free Generative AI Workshops aimed at helping firms explore the potential of generative AI. In a custom 90-minute session, your leaders can sit down with one of our Principal Data & AI Architects to start turning ideas into a plan of action.
During the session, we will:
Explore use cases for generative AI within your business
Evaluate enterprise readiness to execute on top use cases
Recommended next steps to advance AI for your organization
Appendix — Code & Math
At the heart of the Evaluation Capacity Bottleneck model lies an S-shaped curve that converts evaluator headcount and skill into end-to-end evaluation capacity.
The ECB framework covers ideation to final verdict, meetings, and partial reviews included—until congestion of expert attention stalls the flow:
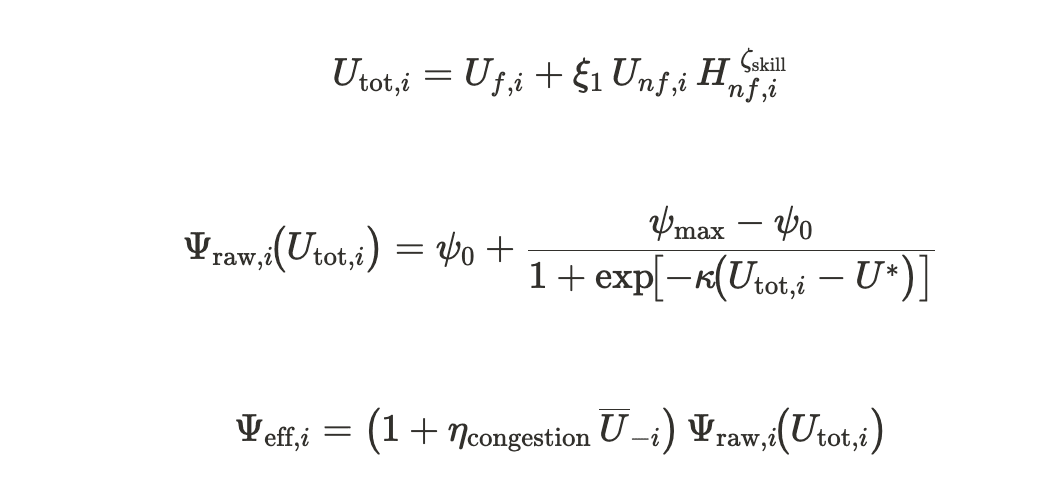
Symbol |
Interpretation |
|---|---|
|
Fungible evaluation capital such as infrastructure, tools, and metrics-observability platform |
|
Non-fungible evaluator capital—the headcount of in-house experts whose skills are not easily rented |
|
Skill level of the evaluators |
|
Multipliers that translate evaluator headcount and skill into effective capital |
|
Baseline and maximum screening throughput |
|
Evaluation-capital level at which throughput reaches half of its maximum |
|
Steepness of the S-curve (how fast throughput rises) |
|
Sensitivity to industry congestion |
|
Average total evaluation capacity across all rival firms |
The open-source repository with simulations, code, and equations is available here.
You can reproduce the baseline runs or plug in your own company data to model scenarios.









