Data engineering teams spend too much time on the gap between a requirement and a working pipeline: profiling sources, mapping columns, writing transforms, and chasing test failures.
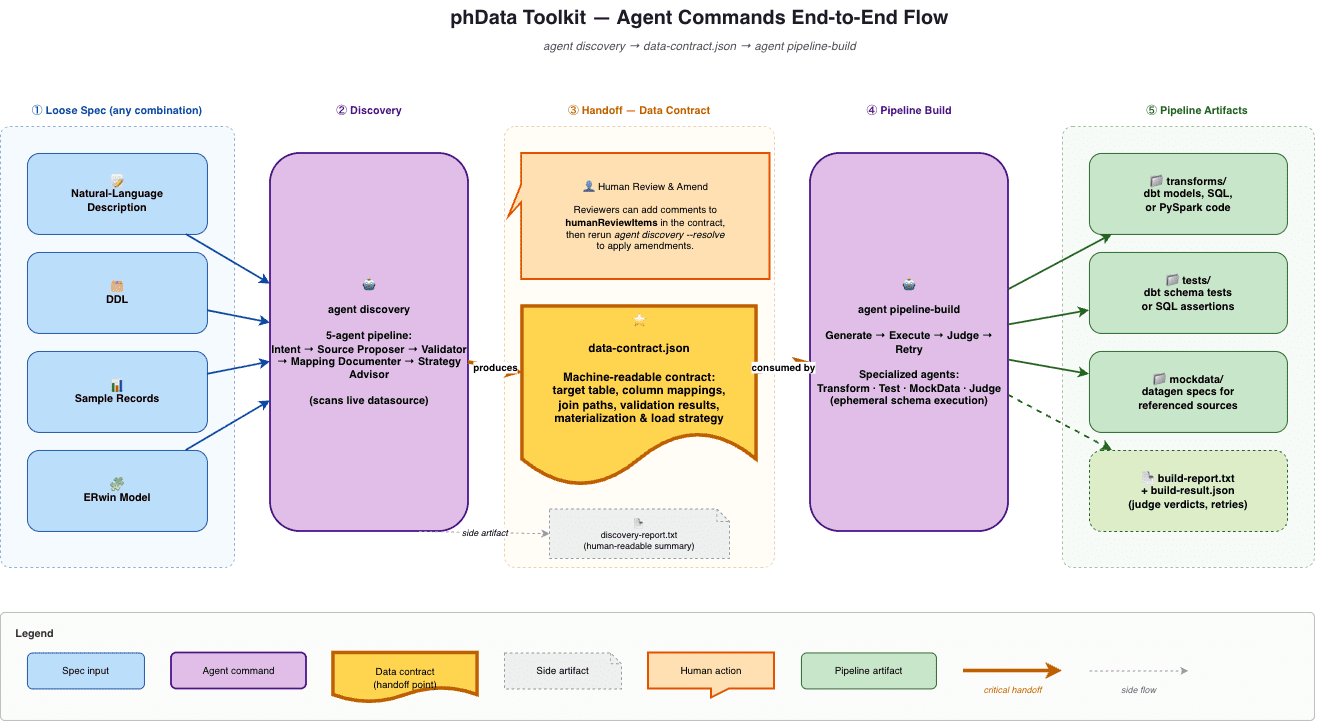
agent discoveryturns a loose spec into a validated, human-reviewable data contract.agent pipeline-buildtakes that contract and produces execution-ready transforms, tests, and mock data through a generate-execute-judge-retry loop.The data contract captures mapping decisions, validation results, and flagged ambiguities in one inspectable artifact, giving humans a structured review surface instead of raw generated SQL.
Tests and datagen specs are contract-anchored, hand-editable deliverables that retain value when teams rewrite the generated transforms by hand.
While many companies are talking about AI’s potential, customers are looking for concrete proof: How is phData actually building pipelines in an AI world? The answer lies not in monolithic, “from-scratch” code generation, but in a structured, engineering-led approach that ensures reliability and auditability, qualities that are often missing in competitor’s AI results.
Data engineering teams spend a disproportionate amount of time on the connective tissue between a requirement and a working pipeline, including profiling sources, hand-mapping columns, writing transforms, generating mock data, and chasing test failures. The work is necessary, but often tedious, which makes it a strong candidate for agentic automation.
We’ve added two agents to the phData Toolkit that target exactly this gap: agent discovery and agent pipeline-build. The discovery agent turns a loose specification into a validated data contract. The pipeline-build agent turns that contract into execution-ready code, tests, and mock data. Together, they form an end-to-end path from “here’s roughly what we need” to “here are the dbt models, tests, and datagen specs, and they pass.”
Both commands target Snowflake and Databricks as platforms today, with final outputs in SQL, dbt, or PySpark depending on what fits the workload and the team’s stack.
This post walks through how agentic automation works, why we structured the commands the way we did, and how they hand off to each other.
The data contract: The seam of agentic automation
Before getting into the commands themselves, the design choice worth calling out is that a data contract sits between them. Discovery produces it. Pipeline-build consumes it. Neither command knows about the other’s internals. They only agree on the contract format.
That separation matters for two reasons. First, the contract is the natural place for human review: discovery is the phase where ambiguity lives (mapping decisions, business rules, materialization tradeoffs), and pulling that into an explicit, editable artifact keeps humans in the loop without forcing them to read generated code. Second, it means each command is independently runnable. You can hand-author a contract and skip discovery, or rerun pipeline-build against an existing contract without re-profiling the source.
agent discovery: from spec to validated contract
agent discovery takes a registered datasource and a YAML/JSON config containing the specification, tooling preferences, target platform, and load strategy hints. It produces two artifacts: discovery-report.txt for humans and data-contract.json for downstream tooling.
The “spec” can be almost anything teams already have lying around, a natural-language description, raw DDL, a handful of sample records, an ERwin model, or some combination. The job of discovery is to harmonize that input with what’s actually in the live datasource and produce a contract that both reflects intent and is grounded in real metadata.
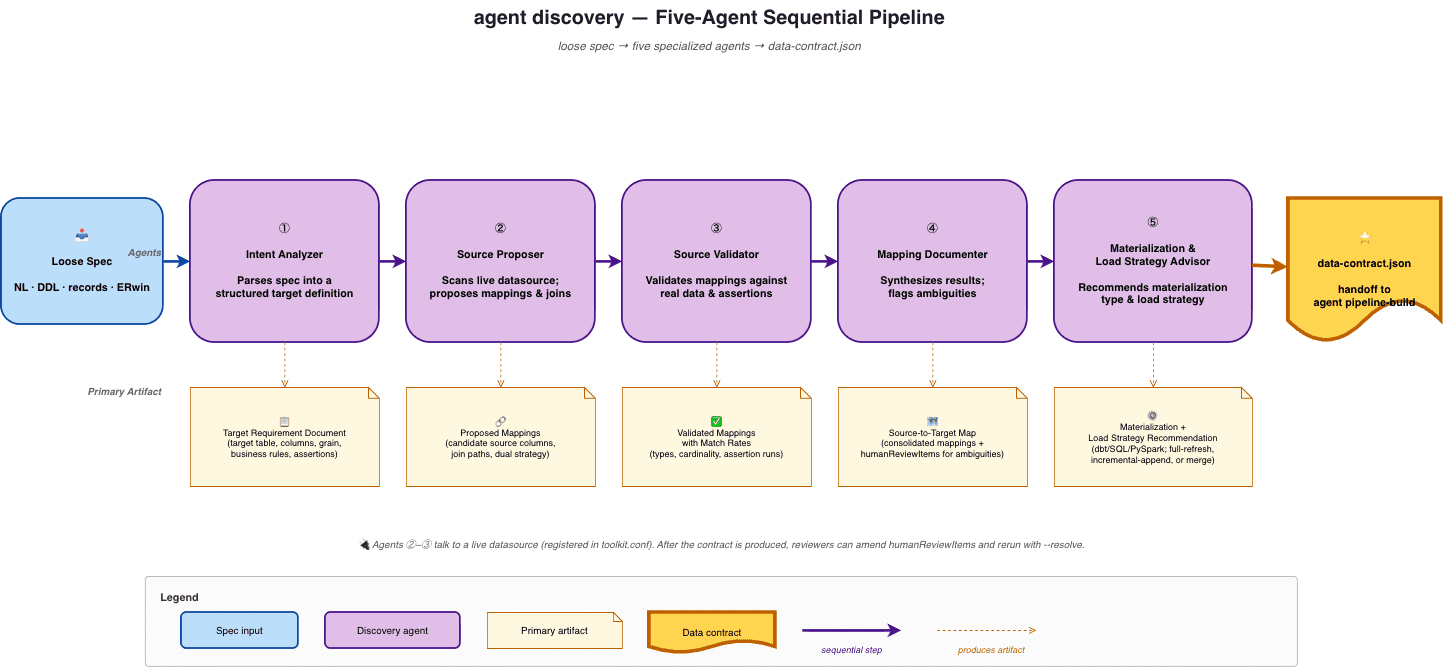
A five-agent sequential agentic automation pipeline
Discovery runs as a sequence of five specialized agents, each producing input for the next:
Intent Analyzer parses the spec into a Target Requirement Document, target table, columns, grain, business rules, and assertions. This is the agent that turns informal language into something structured. A spec like Build a customer table with their full name, lifetime order count, first order timestamp, lifetime spend including tax, and the menu type they order most often. becomes a structured target: grain of
customer_id, columnscustomer_name(derived from concatenated first/last name),count_lifetime_orders,first_ordered_at,lifetime_spend,most_common_menu_type, business rules capturing the tax-inclusive spend definition and the name-concatenation logic, and assertions like uniqueness oncustomer_idand non-negative counts.Source Proposer scans the live datasource’s metadata and profiles, then proposes column mappings and join paths against the requirements from step 1.
Source Validator takes those proposals and validates them against actual data — checking types, cardinality, and assertion behavior — and reports match rates rather than binary pass/fail.
Mapping Documenter synthesizes the validated mappings into the final source-to-target map and explicitly flags ambiguities for human review.
Materialization & Load Strategy Advisor recommends a materialization (Table, View, Merge, etc) and a load strategy (full-refresh, incremental-append, incremental-merge) consistent with the grain, volume profile, and tooling preferences declared in the config.
Splitting these responsibilities matters. Each agent has a narrow job and a narrow context, which keeps prompts focused and makes failures easier to attribute. It also makes the pipeline easier to extend, where adding a new validation step or swapping out the materialization advisor doesn’t require touching the others.
Human-in-the-loop with --resolve
A discovery contract isn’t always immediately final. Mapping ambiguities, business rule edge cases, and materialization tradeoffs frequently need a human call. Discovery surfaces these as humanReviewItems in the contract.
The workflow is:
Run
agent discoveryand review the contract.Add inline comments to any
humanReviewItemsyou want to change.Rerun discovery with
--resolve. A Review Resolver agent applies the amendments and regenerates the contract.
This avoids the failure mode where a human edit and a regenerated contract drift out of sync. The contract stays the source of truth, and review comments are a first-class input rather than out-of-band Slack threads.
Reconciliation, not just generation
Two reconciliation steps are worth highlighting because they’re easy to underestimate:
Target table name reconciliation: the agent checks the proposed target name against the live source catalog and resolves collisions or naming-convention mismatches before the contract is written.
Materialization vs. load-strategy reconciliation: some combinations (e.g., full-refresh on a streaming-shaped table, or incremental-merge without a usable merge key) are inconsistent. The advisor agent reconciles these explicitly rather than emitting a contract that pipeline-build will later choke on.
Inside the data contract
The contract is a complete record of how discovery reasoned about the spec, what it learned from the live source, and what tradeoffs it made. The structure is intentionally verbose because both humans (during review) and downstream agents (during pipeline-build) need to be able to inspect it.
The top-level shape:
targetTable,targetPlatform,tooling,computeType: deployment metadata: the fully-qualified target table, the platform (Snowflake or Databricks), the output language (SQL, dbt, or PySpark), and the compute model.grain: the columns that define one row in the target.columns: every target column withdataType,nullable, and agent-writtenbusinessMeaningandderivationNotes. The notes are how a human reviewer (or a downstream agent) understands intent without re-reading the spec.businessRules: natural-language rules captured from the spec, kept verbatim so they carry through to test generation.edgeCases: explicit edge cases the agents identified, each with affected columns and example scenarios (zero-count customers,NULLhandling, tie-breaking, refund-driven negatives, malformed timestamps, missing references).exampleRecords: concrete source-to-target examples used by validation and downstream by mock data generation.testAssertions: assertions that have already been run against real data, with results.materializationSpecandloadStrategy: materialization type with schema-change policy, plus load strategy (e.g.INCREMENTAL_MERGE) with watermark column, change detection method, delete handling, and the agent’s reasoning preserved inline.sourceToTarget: the analytical core: column mappings with confidence scores, validated join paths, source tables used, warnings, and thehumanReviewItemsqueue.
A few excerpts from a contract make the shape concrete.
A column mapping carries the actual transformation, a confidence score, the agent’s evidence, and the alternatives it considered and rejected:
{
"targetColumn": "most_common_menu_type",
"sourceTable": "DEMO_DB.RAW_POS.MENU",
"sourceColumn": "MENU_TYPE",
"transformation": "MODE() WITHIN GROUP (ORDER BY m.MENU_TYPE) OVER (PARTITION BY oh.CUSTOMER_ID)",
"confidence": "MEDIUM",
"confidenceScore": 0.644,
"evidence": "MENU_TYPE exists in MENU and can be tied to customers through orders and order details. ... | WARNING: join involving DEMO_DB.RAW_POS.MENU failed validation",
"alternatives": [
{
"source_table": "DEMO_DB.RAW_POS.CUSTOMER_BASICS",
"source_column": "MOST_COMMON_MENU_TYPE",
"reason": "Raw derived table already contains the final metric."
}
]
}
The evidence field carries both the agent’s reasoning and a downstream warning from join validation. The contract keeps that audit trail visible rather than collapsing it into a single confidence number.
Join paths are validated against real data and the result is recorded inline:
{
"leftTable": "DEMO_DB.RAW_POS.ORDER_DETAIL",
"rightTable": "DEMO_DB.RAW_POS.MENU",
"joinCondition": "ORDER_DETAIL.MENU_ITEM_ID = MENU.MENU_ITEM_ID",
"validated": false,
"validationResult": "match_rate=45.00%, cardinality=1:1, left_rows=20, right_rows=12, joined_rows=9"
}
A 45% match rate is exactly the kind of signal a “confidence: high” stamp would have erased. Preserving the raw validation result lets a human see that menu items are being orphaned and decide what to do about it.
Human review items surface ambiguities the agents flagged for human resolution, categorized by what kind of decision is needed:
"humanReviewItems": [
{ "description": "[SPEC AMBIGUITY] Tie-break logic for most_common_menu_type is not defined when multiple menu types share the same highest frequency." },
{ "description": "[JOIN FAILED] DEMO_DB.RAW_POS.ORDER_DETAIL -> DEMO_DB.RAW_POS.MENU on MENU_ITEM_ID: match_rate=45.00%. Please verify the join condition." },
{ "description": "[MULTIPLE CANDIDATES] customer_id has 3 alternative source mappings. Selected: DEMO_DB.RAW_POS.CUSTOMER_LOYALTY.CUSTOMER_ID. Please verify this is the authoritative source." }
]
The bracketed prefixes, [SPEC AMBIGUITY], [JOIN FAILED], [MULTIPLE CANDIDATES], [COMPLEX TRANSFORM], let a reviewer triage the queue rather than working through it linearly.
Edge cases and example records round the contract out. Edge cases are enumerated by category (zero_count, null_handling, tie_breaking, boundary, type_coercion, missing_reference) with affected columns and a worked example for each. Example records pair source values with the expected target row, giving pipeline-build a concrete reference for both correctness checking and mock data generation.
The verbose format is deliberate. The contract carries the audit trail of every decision, not just the output, and the audit trail is what makes the workflow reviewable, repeatable, and amendable.

Accelerate your data projects with the phData Toolkit
See how agentic automation collapses data engineering boilerplate from days to hours.
agent pipeline-build: From contract to executable artifacts
agent pipeline-build takes a datasource name, the data-contract.json from discovery, and a retry budget (default 3). It produces:
transforms/, dbt models, SQL scripts, or PySpark code, depending on the platform declared in the contracttests/, dbt schema and singular tests, or datasource test config and SQL assertionsmockdata/, datagen specs using the Toolkit datagen tool for any sources referenced by the transformsbuild-report.txtandbuild-result.json, a human summary and a machine-readable result
Pipeline-build generates, executes, judges, and retries artifacts in a controlled loop. Plenty of tools stop at generation or even just check syntax.
Generate → execute → judge → retry
On a first attempt, pipeline-build runs three generation agents in parallel:
TransformBuilder produces platform-specific transform code.
TestGenerator produces tests and assertions consistent with the contract’s business rules.
MockDataGenerator produces datagen specs for the referenced sources, sized and shaped to exercise the transforms.
The parallel-on-first-pass design is deliberate. These three artifacts have soft dependencies (transforms reference sources, tests reference transforms) but in practice they can be drafted independently from the same contract, and parallelizing them roughly thirds the wall-clock time on the initial pass.
After generation, the pipeline runs a small post-processing pass: output-swap detection (catching cases where TransformBuilder and TestGenerator wrote each other’s content), YAML deduplication, and an optional dbt fix pass for known cosmetic issues.
The execution phase is where most agentic codegen tools stop being useful. ExecutionRunner spins up an ephemeral schema, loads the mock data, compiles and runs the transforms, executes the tests, and tears the schema back down. If dbt fails, an optional DbtFixAgent attempts surgical patches before the run is declared a failure, handy for the long tail of small, deterministic dbt errors that don’t need a full regeneration.
The judge phase is handled by PipelineJudge, an LLM agent that evaluates the run holistically: correctness against the contract, test coverage, DAG (directed acyclic graph) structure, and performance risk. The judge doesn’t just grade the output, it assigns severity (CRITICAL, MAJOR, etc.) and attributes blame to specific generation agents. A failing test might be the test’s fault, the transform’s fault, or the mock data’s fault. The judge has to say which.
That blame attribution feeds the retry loop.

What makes the loop converge
Two design choices keep the retry loop from spinning:
Targeted regeneration. Only agents blamed for
CRITICALorMAJORissues regenerate. Everyone else reuses their prior output. This avoids the common failure mode where a perfectly good transform gets rewritten because a test happened to fail, drifting further from correct on each pass.Cross-context injection. Each regenerating agent sees the other agents’ current output read-only. The TestGenerator on retry knows exactly what transform it’s testing; the TransformBuilder on retry knows exactly which tests it needs to satisfy. This is the difference between agents collaborating and agents talking past each other.
A third safeguard, oscillation detection, terminates the loop early if the same issues keep recurring across attempts. A retry budget of 3 is the default, but oscillation detection often stops sooner when it’s clear the model isn’t going to converge on the current contract, which is itself useful signal: it usually means the contract has a real ambiguity that should go back through discovery’s --resolve flow.
The tests and datagen specs are first-class deliverables
It’s tempting to think of tests/ and mockdata/ as build-loop scaffolding, generated so the judge has something to run, then forgotten once the transforms pass. They’re more useful than that, and worth talking about on their own terms because they’re often what teams want even when they don’t end up using the generated transforms. Both are produced as hand-editable, contract-anchored artifacts, which means they retain value independently of whatever code pipeline-build emits alongside them.
Tests as standalone artifacts. TestGenerator produces tests directly from the contract’s business rules and assertions, not by inspecting the generated transforms. That means the tests are valid against any implementation of the same contract, including hand-written code. Teams that prefer to author transforms manually can still consume the generated tests as a starting point: drop them into their own dbt project or SQL test harness and use them as regression checks when the underlying pipeline changes. The tests also tend to surface contract-level issues that aren’t obvious from the spec alone, since they make implicit business rules executable.
For dbt platforms, the output is a mix of schema tests in YAML (uniqueness, not-null, accepted values, relationships) and singular tests in SQL (cases where a business rule needs custom logic). For SQL and PySpark, the ds test artifacts make it easy to plug them into a normal QA process.
Datagen specs grounded in real source observations. The mock data isn’t random. MockDataGenerator builds its specs from the example records, edge cases, and join cardinalities the contract captures, concrete source-to-target scenarios from validation, an enumerated list of awkward cases (zero-count customers, null name components, refund-driven negatives, orphaned references), and the actual match_rate and joined_rows figures from each join path. The result is mock data that exercises the transforms in approximately the way real data would, including the awkward bits the contract already flagged.
Common follow-on uses for the datagen specs:
Local development without needing a copy of, or a connection to, the production source.
CI pipelines that have to run end-to-end without touching real systems.
Reproducing customer-reported issues by editing the spec to inject the specific edge case that triggered a bug.
Training and onboarding environments where the data needs to look realistic but be synthetic for compliance reasons.
Because both artifacts are decoupled from the transforms — tests reference the contract, datagen references source profiles — they remain useful when a team rewrites the pipeline by hand later. Same separation-of-concerns argument as the contract itself: each artifact retains value independent of the surrounding code.
Why not just let an agent build it from scratch?
A reasonable objection at this point is: why not skip the structure entirely? Hand a frontier model the spec, give it source access and a sandbox, and let it generate transforms, tests, and mock data in one shot. Agentic automation without a human in the loop works in the demo. It tends not to work in production, and it’s worth being explicit about why.
Cost. A monolithic agent loop has no notion of which artifact failed and which is fine, so a single test failure on attempt three can trigger a full regeneration of transforms, tests, and mock data, every time.
pipeline-build‘s targeted regeneration only reruns the agents the judge blamed forCRITICALorMAJORissues. On a typical retry, that’s one agent regenerating against the others’ frozen output, not three agents rebuilding from scratch. Across a real workload, the difference is roughly an order of magnitude in tokens, and the budget is fixed rather than open-ended. The same logic applies to discovery: five agents with narrow contexts each see the slice of metadata they need, not the entire source catalog plus the full spec on every call.Convergence. Without explicit stop conditions, an agent given build me a pipeline will keep tweaking, fixing one test, breaking another, second-guessing a column choice it made two turns ago. A common pattern:
TestGeneratortightens an assertion to satisfy the judge →TransformBuilderrewrites the transform to satisfy the new assertion → that rewrite breaks a different assertion →TestGeneratorloosens the second one → the loop spins.pipeline-buildcatches exactly this with oscillation detection: if the same agents are blamed for the same kinds of issues across consecutive attempts, the loop terminates and the failure is surfaced as a contract-level problem instead of pretending more retries will help. The retry budget, severity gating, and oscillation detection together give the loop a defined success criterion (the judge’s verdict) rather than the model’s own sense of “good enough.”Reviewability. A from-scratch agent gives you a pipeline and a reasoning trace. The pipeline is reviewable in principle, but you have no leverage to change it short of re-prompting and hoping. With discovery + contract, the human review surface is the contract itself, a structured document with explicit
humanReviewItems, edited inline and re-resolved. You’re reviewing decisions, not generated SQL.Validation. Source Validator runs proposals against the live datasource and reports match rates. A monolithic agent will confidently propose a join on a column that doesn’t exist, or assume a type that the source actually stores as a string. While the agent can be set up to query to determine these things, it is another bit of context that is used or time that is spent for the agent to write the code. The deterministic tool the Source Validator uses makes it much easier and faster. The five-agent split exists partly so that proposing and validating are different jobs done by different agents, where the proposer is allowed to be optimistic, and the validator is the one that has to be right.
Observability.
PipelineJudgeattributes blame to specific generation agents. That’s how the retry loop knows what to regenerate, but it’s also how a human debugging a stuck build knows where to look. A monolithic agent that produced a broken pipeline gives you no such handle, the failure is the whole thing, and your only recourse is to re-prompt the entire job.
Why we split into two commands
These two commands could have been one. We split them because the failure modes are different and the human checkpoints belong in different places.
Discovery’s failures are about understanding: did we read the spec right, did we map to the right columns, did we pick a sensible materialization? Those failures want a human reading a contract, not a human reading generated SQL.
Pipeline-build’s failures are about execution: does the code compile, do the tests pass, is the DAG sane? Those failures want an automated loop with judging and retry, because most of them are mechanical and the rest are caught by the judge.
Keeping the contract as the seam means each command can evolve on its own cadence. Discovery can get smarter about source profiling without touching pipeline-build. Pipeline-build can add a new platform target (Snowpark, Spark SQL, whatever’s next) without touching discovery, as long as the contract format covers it.
What this means in practice
The immediate win is that the boilerplate phase of a new pipeline collapses from days to a reviewable contract plus a build report. The work that’s left is the work humans should be doing anyway, like confirming intent, resolving genuine ambiguities, and reviewing what the judge couldn’t fully verify.
A representative case: a new table over CUSTOMER_LOYALTY, ORDER_HEADER, ORDER_DETAIL, and MENU on Snowflake. Discovery surfaces three things in the contract that need a human call: the ORDER_DETAIL → MENU join validates at only 45% match rate (orphaned MENU_ITEM_ID references), the spec didn’t define tie-break behavior for “most common menu type,” and ORDER_HEADER.ORDER_TOTAL is the only available proxy for tax-inclusive lifetime spend. All three appear as categorized humanReviewItems ([JOIN FAILED], [SPEC AMBIGUITY], [SPEC AMBIGUITY]). The team annotates them, reruns with --resolve, and pipeline-build produces SQL transforms, assertions covering grain uniqueness and non-negative metrics, and a datagen spec that exercises the orphaned-reference case explicitly. The boilerplate phase that would have taken a week becomes a few hours of focused review.
For customers, these commands are the visible surface of a longer effort to make the Toolkit agentic where agents help and deterministic where determinism matters. Generation is agentic automation. Execution and judging are deterministic loops around agentic outputs. Contracts and reports are inspectable artifacts, not opaque chains of thought.
If you want to try them, both commands ship in the current Toolkit release. You can get started immediately by visiting the phData Toolkit page to download the latest release and start with agent discovery against any registered datasource. The build report will tell you what the judge thought, what got retried, and why.
FAQs
What are the core benefits of phData Toolkit's agentic commands?
The phData Toolkit uses agentic automation via discovery and pipeline-build commands to collapse data engineering boilerplate from days to hours. It provides a structured, engineering-led approach that ensures reliability and auditability while automating profile source mapping, transform writing, and mock data generation.
How does the data contract facilitate human oversight in AI pipelines?
The data contract serves as a transparent “seam” where humans can review mapping decisions, business rules, and materialization tradeoffs. By using the –resolve flag, teams can annotate humanReviewItems inline, ensuring the AI remains grounded in real business requirements without requiring reviewers to read generated code.
Which platforms are supported by phData's agentic automation?
Both agent discovery and agent pipeline-build currently target Snowflake and Databricks as primary data platforms. The agents reconcile target names and load strategies against live source catalogs to ensure platform-specific compatibility.
What output languages does the phData Toolkit generate?
The toolkit generates execution-ready artifacts in SQL, dbt (models and tests), and PySpark. This flexibility allows teams to integrate agentic outputs directly into their existing technical stacks and CI/CD pipelines.


