

It’s nearly impossible to watch the news without hearing the term cybersecurity. Just recently, hackers breached the networks of thousands of private companies and government organizations by attaching malware to a single software update from a company called Solarwinds. This single breach granted access for several months and leaked an unprecedented amount of information, most of which was stolen without a trace. There is little doubt that these incidents made companies and governments more afraid and protective of their data and networks.
It only takes an innocent-looking email with a malware attachment to infiltrate the computer system.
Spam accounts for a whopping 48 percent of email traffic, most of which is not analyzed for risk. In many cases, only a small amount of email is scrutinized and the rest remains unhandled.
The rise in the volume and variety of the data generated at the internet of things (IoT) devices has exposed the limitation of cloud computing. In many cases, it is impractical to log large volumes of data to a central location for artificial intelligence (AI) methods to run a learning algorithm. Likewise, it is impossible to centralize data when it’s confidential and owned by different entities.
These concerns gave rise to new machine learning (ML) techniques to help overcome privacy and massive data volume issues. Experts have proposed many different algorithms to solve these issues; the most popular is federated learning (FL). Federated learning addresses the cybersecurity vulnerabilities by moving the computation to the edge rather than centralizing the data to run the learning process.
In this article, we’ll discuss the basic principles of federated learning and cover how it can be used to create a spam filter with a dataset of emails.
What is Federated Learning?
Federated Learning is a technique that enables one to learn from a broader range of data that is distributed across different locations and seeks to reduce the data movement from the edge nodes (devices) to the central server (on-prem or cloud).
This is achieved by collaboration with other edge nodes. Each node creates its local model using local data. These locally trained models are securely sent to the server to be consolidated into a single or multiple global model(s) then sent back to the devices in order to perform predictions.
Understanding Federated Learning
The theory behind federated learning is as deep as its core component: the well-known deep learning neural network (see Figure 1). Intuitively, each edge node (client) keeps its data locally and trains its local model.
Each local model can be trained with different numbers of observations. The server updates the global model accounting for the number of samples received from each model. Furthermore, the communication to the server from the edge nodes is asynchronous, which means that the server does not wait for an immediate answer after asking an edge node to participate in updating the global model. This is highly desirable in terms of efficiency.
Note that the edge nodes maintain confidentiality by only accessing its local data and not sharing data with other nodes. The local model weights are then sent over to the central FL server to be combined into a single global model.
The server may use different strategies to update the global model. Once the model is complete, the server sends it back to all participating edge nodes. Each edge node now has all the insights collected from all other edge nodes without having seen their data.
While most applications of AI and ML are used by companies to gain a competitive advantage, there are other contexts where companies have incentives to work together; cybersecurity is a prime example. In this case, the goal is to combat a common threat, which is to block the hackers before breaching their internal networks and infecting their computer systems.

Federated learning schematic illustration of the infrastructure
How Federated Learning Applies to Cyber Security
Let’s envision a cybersecurity company protecting multiple organizations where the data cannot be centralized nor shared. Moreover, building one model for each customer is not practical. Granted that the hackers can easily change the content of the spam, it’s possible they could render the spam detection application useless. Coupled with the performance limitation, it is common for security applications to omit the header information and the body of an email message only to include the email subject line.
To illustrate how federated learning can impact an organization’s predictive capabilities, let’s look at an example with two different spam email datasets. Specifically, let’s imagine a use case where we need to predict whether an email is ham (legitimate) or spam provided from different data sources.
In this section, we’ll:
- Analyze two datasets and build a classification model
- Discuss the results
- Illustrate the problem where the hackers change the content
- Explain global model update strategies
- Highlight the power of using federated learning
Analyzing the Datasets
First up is the SMS spam collection dataset that has been collected for SMS spam research. It contains one set of SMS messages in English of 5,574 messages, tagged according to ham or spam.
Analyzing the spam dataset (see Figure 2), we notice that spam messages contain words like free, urgent offer, text stop, sexy, call, claim, now, etc. In contrast, Figure 3 shows the ham messages: home, just come, want, ok, time, later. This gives us insight into what spam and ham messages look like.

Now that we have a basic understanding of what the dataset looks like, we can go ahead to prepare the dataset for training and building a model.
Building a Deep Learning Model
We will build a very simple deep learning model (see Figure 4) to emphasize the benefit of using FL. By the same token, we intentionally leave out many of the typical machine learning optimization techniques. In practice, the optimization would be performed offline, and the optimal strategy applied to the FL.
Like building legos, deep learning has layers of different building blocks. The model architecture input will comprise an embedding layer used for text data. This helps with the mapping of higher-dimensional text data to lower-dimensional features that can be easily trained. The embedding layer provides a representation of words to help the model understand which words are similar and which are different.
Next, we add a flatten layer to reshape the embedded vocabulary as an input for the next couple of dense layers (just a regular densely connected neural network) before the final sigmoid layer, since this is a binary classification problem where the outcome is ham or spam. The dropout layer helps prevent overfitting. Dropout is a simple and powerful regularization technique for neural networks and deep learning models.

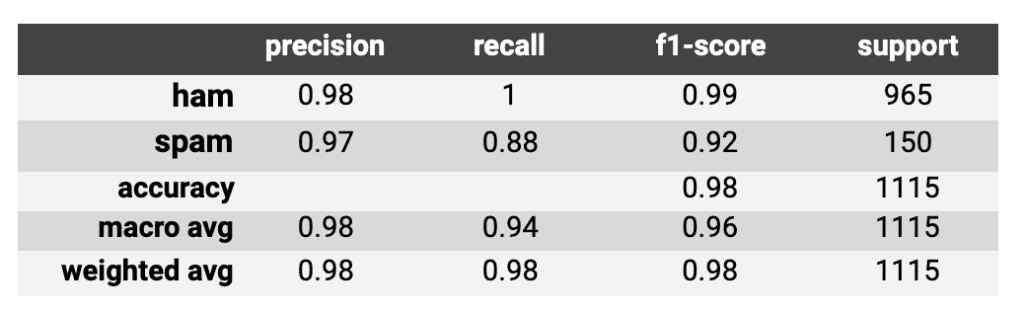
Table 1: Show the classification report from running the SMS model
The SMS model performance looks good, and we are ready to introduce the next dataset from Enron Corporation. The Enron dataset comprises six datasets each containing ham and spam messages in English from a single user of the Enron corpus. The total data size of 33,716 messages (we suggest reading the original paper for a deeper understanding).
Analyzing the spam dataset (see Figure 5), we notice that spam messages contain words like company, subject, click, order, email, offer, time, etc. In contrast, Figure 6 shows the ham messages containing words like company, know, question, let, day, need. This gives us insight into what spam and ham messages look like.

We follow the same process we established for the SMS dataset, employing the same deep learning architecture (See Figure 4). The model trains 50 epochs and stops once it is not improving anymore. The final accuracy from the validation set is around 92 percent as seen in Table 2. This is also a very good accuracy score.

Table 2: Show the classification report from running the Enron model
Hackers Deceptions
Cybercriminals have a lot of tools to threaten your Internet security. For instance, the hackers can change the content of the email messages so that the model will fail to detect spam or spear-phishing emails. To simulate this scenario we start by using the trained SMS model to predict spam from the Enron dataset.

Table 3: Classification report from running the SMS model predicting Enron dataset
Individually training each model achieved above 90 percent accuracy. Unfortunately, we can see from Table 3 that the accuracy plunged to 54 percent once the model sees new content. The result is slightly better than random. How about using the Enron model to predict the SMS dataset?

Table 4: Classification report from running the Enron model predicting SMS dataset
The accuracy is 57 percent which is marginally better than the previous test—but not a production worthy model. Can this problem be overcome by utilizing federated learning? The short answer is yes (the longer answer is below).
Strategy to Update Global Model
In this section, we dive deeper into the strategy used by the server to combine all the client’s models (I promise to only use math in this section).
Once the server receives the client’s models, the server starts parallelly combining the models. In our example, we combine the two trained models by adapting the parallelized variant of the stochastic gradient descent (SGD) algorithm, similar to the one proposed by Chen et al.
After each client trains its local model based on its local dataset, the trained models are sent to the server to be aggregated by computing a weighted average of all the deep learning layers (see Figure 4) in the neural network models.
There are many strategies to compute the weighted average:

Where N is the number of samples on each client.
For simplicity, we use the second approach where we update based on the linearly decreasing weighted average.

Table 5: Classification report from combining the two models predicting Enron dataset
The result looks good after combining the two models for predicting Enron datasets. Table 5 shows 88 percent accuracy and a 63 percent improvement after combining the models.
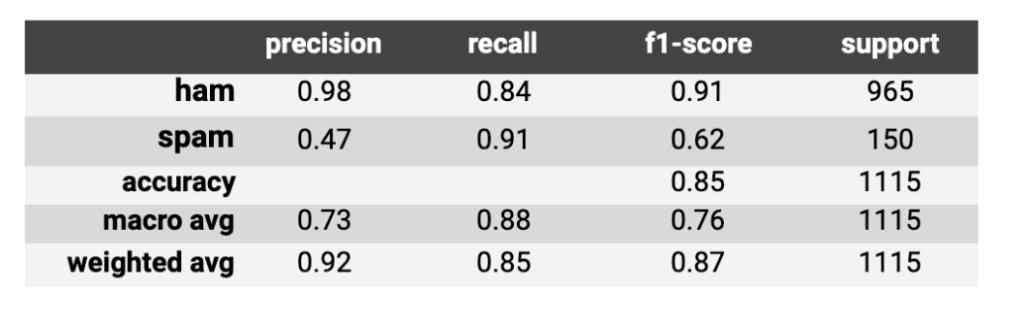
Table 6: Classification report from combining the two models predicting SMS dataset
We can also observe the same for the SMS dataset with 85 percent accuracy and a 49 percent improvement after combining the two models.
In this post, we only discussed one global model that represents all the models, which is in our case the Enron and SMS spam models. There have been proposals to perform clustering on the server-side to find groups of similar models and aggregate on a subset of models. The argument is, with heterogeneous data that comes from different locations and sources, one model can not possibly represent it all.
The performance can be dramatically improved by keeping multiple global models. Moreover, clustering can be used to detect anomalies. For instance, hackers can create a malicious model that corrupts the model’s ability to detect spam, even though the communication between the client and server in FL is secured, hackers always find a way in.
Stay tuned for a future post where we discuss clustering used in the server-side of the federated learning and FL for time series.
Adapting at-Scale with MLOps and Automation
Dealing with cybersecurity is an ongoing battle between hackers and cybersecurity engineers and data scientists, especially in the wake of events like the current exploit on the US government that triggered widespread malware and unpredictable widespread changes in the software.
In fact, the number of known malware samples have already surpassed the one billion mark. It’s critical to keep evolving your technology stack to cope with cybercriminals’ sophisticated attacks.
When AI and ML models are unable to adapt to fundamental changes in underlying data patterns, accuracy in detecting malware is bound to suffer. This not only undermines businesses’ investments in those technologies but also leaves them exposed to cyber threats as they’re unable to make informed, data-driven decisions in response to a chaotic and fast-evolving situation. Even if you strive daily to protect your data and keep the cybercriminals at bay, it requires businesses to collaborate to maximize their security. That is where FL can shed some light.
Because these pattern shifts tend to occur in real-time and in stealth (even as data continues to pile up), preparing for intrusions can be a major challenge. That’s why it’s so important to ensure ML data pipelines and models are built with automation and visibility in mind. Data science teams need a programmatic MLOps framework to:
- Sustainably deploy and maintain ML models into production
- Handle model versions and model selections
- Monitor for anomalies and other performance issues
- Manage the dynamic nature of ML applications with the ability to refit, update, and prepare data in distributed environments
All of that needs to happen on the fly while continuing to provide the highest quality of services for business applications.
That means you need both the cybersecurity engineers and data science expertise know-how to automate and monitor pipelines in a sustainable, systematic way. Only then can you be confident in your ability to deal with cybercriminals in the wake of a seismic event like the exploit on the U.S government and private companies, and continue getting value from your data.
Does Your Organization Have a Use Case for Federated Learning?
At phData, we have experience solving tough machine learning problems and putting robust solutions into production.
Whether you need to develop a novel proof of concept, see an enterprise-level project through from inception to deployment, or you just need an expert partner that can evaluate your current systems to determine your potential risk in the event of an unforeseen disruptive event, phData’s Machine Learning practice is here to help!
Get in touch with us today!
Federated Learning FAQ
Federated Learning is distributed machine learning that can learn from distributed data and machines using a central server for coordination. Each node creates its local model using local data. These locally trained models are securely sent to the server to be consolidated into a single or multiple global model(s) then sent back to the devices in order to perform predictions.
Yes, the communication between the edge nodes and the server can be secured with traditional network security protocols.
Yes, the deep learning algorithms support Time Series forecasting.
Yes, the server-side can use clustering to train multiple global models and share models with its relevant edge nodes.









