

Cortex Analyst is a Generative AI offering from Snowflake AI Data Cloud that allows users of all technical abilities to query data sets using natural language instead of SQL. As part of Snowflake’s continuing efforts to improve its data platform, they have recently released two new features to make the experience of setting up and using Cortex Analyst even smoother.
The first is the semantic model generator. It is a tool for speeding up the creation and updates of the semantic models that power Cortex Analyst applications.
The second is the Verified Query Repository (VQR). Think of this as an added context helper for Cortex Analyst. With VQR, you can now add queries to your semantic model to help train it to answer more questions in a desired manner.
In this blog, we will be walking through these two new features and go through some examples of how they work.
Our Data Set
Similar to the data set from our prior article on this topic, we will work with a test AirBnB data set. However, in this case, we’ll structure it slightly differently to demonstrate handling multiple tables via a view. Here are the three tables:
Listing table:

Status Table:

Main Table:

Here is the code to join the tables together for our view:
CREATE OR REPLACE VIEW test_airbnb AS (
SELECT
CONFIRMATIONID
,status
,GUESTID
,NUMADULTS
,NUMCHILDREN
,STARTDATE
,ENDDATE
,BOOKED
,listing
,EARNINGS
FROM SANDBOX.AVIGNEAU.test_airbnbdata a
JOIN test_airbnblisting l ON a.listingid = l.listingid
JOIN test_airbnbstatus s ON s.statusid = a.statusid
With that in mind, let’s dive into the new features of Cortex Analyst.
Semantic Model Generator
The semantic model is a key component of any built-in Cortex Analyst application. It provides the necessary context and mapping of the table to be properly understood and analyzed by the Cortex Analyst.
Unfortunately, filling out it can be a bit cumbersome, especially if it is a table with many columns and added filters. The Semantic Model Generator helps to speed up semantic model development. All you have to do is point the generator at the target table, and it will autofill most of the different components of the semantic model for you.
Model Generator Setup
The setup for the semantic model generator is fairly simple and starts with Snowflake’s repository. You can pull down the repository here and put in your configurations to set up the model generator. All the information you need is in the README. From there, you have different options for running the model generator, a Streamlit app, directly through Python or the CLI tool. For our demonstration, we’re going to look at the Streamlit app.
The Streamlit app provides a helpful UI to help you build your semantic model. At the outset, you can edit an existing model or create a new one from scratch. One thing to note is that when the model generator asks about editing an existing model, it only refers to models built using the generator, not those that may have been edited and placed into a stage some other way.

Then, you fill out information about the table/view at which you wish to point your model. Note that although the selections say Databases/Schemas/Tables, you can only include one table in a Semantic model for Cortex Analyst.

After putting in your table information, you will be presented with a partially filled-out Semantic model YAML file. You will still need to fill out some information like synonyms, descriptions, and filtering information. This will be indicated by <FILL-OUT> . This saves by performing the tedious task of filling out most of the semantic model.

Once you fill out the fields you need to, hit the Validate button, and you will be able to start asking test questions in the chat panel on the right side of the screen. Think of this as your testing ground. You can ask questions, see the output, and then make iterative changes to your model.
When you ask questions in the provided chat window, you’ll see the same SQL statement and output as a normal Cortex Analyst app. For our example, we just asked, “How many stays were booked in 2024?”. We noticed that there are a couple of aspects of the generated SQL statement we want to change.
You’ll notice that there is now the option to Edit and Save as Verified Query. These options refer to the next feature of Cortex Analyst, the Verified Query Repository. With this feature, we can now update how our Cortex Analyst applications understand our data, leading to more consistent answers for end users.

Verified Query Repository
The other new helpful feature for Cortex analysts is the Verified Query Repository (VQR). It’s a way to add helper SQL queries to enhance your Analyst’s ability to answer questions about your data.
In your semantic model, you can map details about individual columns and measures with simple aggregations like sums and counts. But with the VQR, you can include full queries in your semantic model that may add more context than you can express via a singular column.
Example
Let’s return to the Model Generator Setup example, “How many stays were booked in 2024?”. Here’s the SQL we received back from our application:
WITH __test_airbnb AS (
SELECT
startdate
FROM sandbox.avigneau.test_airbnb
)
SELECT
COUNT(DISTINCT startdate) AS num_stays_booked
FROM __test_airbnb
WHERE
DATE_PART(YEAR, startdate) = 2024
-- Generated by Cortex Analyst
;
We would like to update you on a couple of things about this query.
When we refer to questions about booking, we want the analyst to use the
bookedcolumn as its date instead of thestartdate.We don’t necessarily want to count the distinct number of dates when counting the number of stays booked, as more than one stay could be booked on the same day. Instead, we would prefer to use the
ConfirmationID, which is a unique identifier for the stay.While there are some instances where we might want to consider canceled stays in our data, we don’t want the data to consider them as a default, so we should filter them out.
So we can edit the query and re-run the results. Notice that we made all the adjustments we called out in this query. We changed the num_stays_booked definition, the DATE_PART reading the booked column, and filtered out statuses with the word cancel.

Once this result is verified, we can save it in our model as a verified query. This will automatically add it to the verified_queries section of the semantic model.
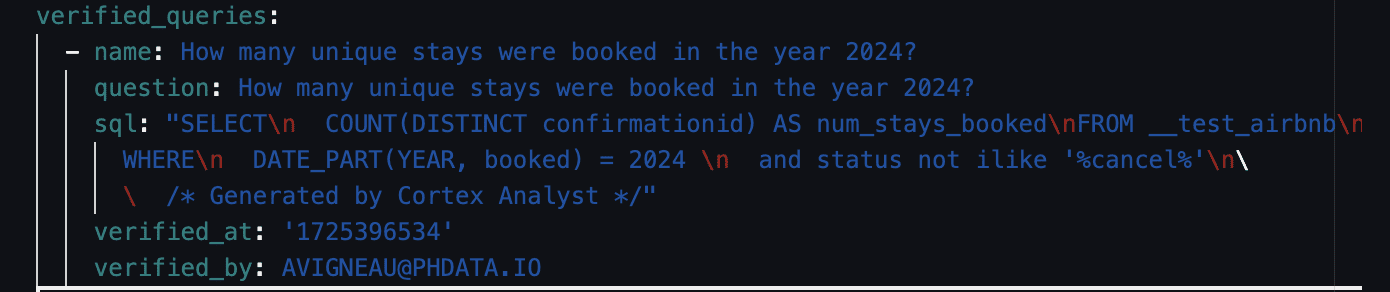
Let’s try another similar query to ensure the logic is sticking.
How many stays were booked between 2024-01-15 and 2024-02-28?

This looks great! The app remembers to exclude canceled stays, correctly counting the distinct ConfirmationIDs and using the booked date for its days. We can continue this testing process within the Semantic Model Generator until we feel confident that it is ready to be released to our end users. This will make the user experience that much smoother and give end users much more confidence in the insights they are receiving.
Let’s look at a more complex example requiring a more complex query: Occupancy Rate.
Example 2: Occupancy Rate
For a more complex example, let’s calculate the occupancy rate. For this discussion, we’ll make the following assumptions:
There are no overlapping stays. A stay ends on one day and begins on a separate one
There are no blackout days. Every day, rent out is available for each property.
We’ll want to calculate the occupancy rate as the number of days stayed divided by the total number of days in the specified time period. Here’s what we get when we ask Cortex analysts for the occupancy rate of the Lively Loft for the first three months of 2024.
WITH __test_airbnb AS (
SELECT
listing,
startdate,
enddate
FROM sandbox.avigneau.test_airbnb
), booked_days AS (
SELECT
listing,
DATEDIFF(DAY, GREATEST(startdate, '2024-01-01'), LEAST(enddate, '2024-03-31')) AS days_booked
FROM __test_airbnb
WHERE
listing = 'Lively Loft' AND startdate < '2024-03-31' AND enddate >= '2024-01-01'
), total_days AS (
SELECT
listing,
DATEDIFF(DAY, '2024-01-01', '2024-03-31') AS days_in_period
FROM __test_airbnb
WHERE
listing = 'Lively Loft'
GROUP BY
listing
)
SELECT
b.listing,
SUM(b.days_booked) / NULLIF(NULLIF(t.days_in_period, 0), 0) AS occupancy_rate
FROM booked_days AS b
JOIN total_days AS t
ON b.listing = t.listing
GROUP BY
b.listing,
t.days_in_period
-- Generated by Cortex Analyst
;
This actually looks pretty good for a first pass. We can see that it is filtering for Lively Loft, calculating the number of days booked and the number of days in the time period. It’s also good that for the start date and end date, it is using the GREATEST and LEAST functions to cap the start date at 2024-01-01 and the end date at 2024-03-31 in case one of the stays started before the time period or ended after the time period specified.
The one tweak I would add is filtering out cancellations in the booked_days CTE for stays. But once I do that, I can save this query, and the analyst tool can leverage it for this calculation moving forward. This is a more complex use case for the VQR and further displays its utility.
Quick Tips
Here’s a quick list of tips for Cortex Analysts:
Pull down the repo for the Semantic Model Generator and use it. It will save you a bunch of time, especially if your target table has a lot of columns.
You can define individual measures with simple aggregations like
SUM,COUNT, andAVG, but if you know there will be more complex logic, utilize the VQR for that. This could include filtering conditions, queries with CTEs, or business logic that the Cortex Analyst wouldn’t immediately be able to infer through natural language.Asking many questions during testing is the best way to determine your Semantic Model needs. You can try asking derivatives of the same question by using synonyms or different periods.
When working with the tool, remember each Analyst app will support only one table or view at a time (for now).
Conclusion
The VQR and Semantic Model Generator are enhancements that allow Cortex Analyst applications to be built faster and produce more consistent results. With VQR, we can provide more detailed context for leveraging the Cortex Analyst tool when providing insights to end-users. With the ability to provide full queries, we can define more complex logic and incorporate multiple columns in our measure definitions.
With the Semantic Model Generator, we have an interface that fills out most of the Semantic Model yaml, provides an interface for testing our application, and lets you pick up a model from where you left off. These enhancements speed up development and give developers more confidence in their Cortex Analyst applications, ultimately providing an even better experience for end users of your applications.
For further assistance with Snowflake Cortex Analyst’s Verified Query Repository and Semantic Model Generator, contact phData’s experts. We’re here to help you optimize these tools for faster development and better insights, ensuring a seamless experience for your end users.









