

Unlike traditional methods that rely on complex SQL queries for orchestration, Matillion Jobs provide a more streamlined approach. By converting SQL scripts into Matillion Jobs, users can take advantage of the platform’s advanced features for job orchestration, scheduling, and sharing.
Additionally, the directed acyclic graph (DAG) feature enables users to easily visualize the relationships between different tasks within a transformation job or different transformation tasks in an orchestration job.
In this blog, we’ll explore how Matillion Jobs can simplify the data transformation process by allowing users to visualize the data flow of a job from start to finish. With that, let’s dive in
What is Matillion ETL?
Matillion ETL is a platform designed to help you speed up your data pipeline development by connecting it to many different data sources, enabling teams to rapidly integrate and build sophisticated data transformations in a cloud environment with a very intuitive low-code/no-code GUI.

How to Translate SQL Scripts Into Matillion Jobs
For the remainder of the blog, we will guide you through the process of translating SQL scripts into Matillion jobs. We will cover the essential components of a Matillion job and provide examples to help illustrate the concepts.
Whether you’re new to Matillion or just looking to improve your ETL skills, keep reading to learn more!
Components
This section will focus on some of the main components available for use in a Matillion Data Transformation job.
Read Components
These are the components that define the source of data that is to be transformed. They vary from the Table Input and Multi Table Input, which define tables from your data instance, the Stream Input for a data stream, or Fixed Flow and Generate Sequence for user-defined inputs.

Join Components
These components define how data from multiple sources are joined together. The most commonly used component of this group will be the Join component, which is equivalent to the Join expression in SQL statements.

Transform Components
These components are used to transform data in a wide variety of ways. As you can see from the menu, a wide range of transformations are configurable via Matillion. We’ll get into a couple of them later in more detail.

Write Components
These components define how the data that has been transformed will be written. Data can be written to a new table or view, appended to an existing table, or updated using Change Data Capture.

Testing
The Assert View is part of Matillion’s “assert components” suite. This component allows users to verify if certain conditions are true of a view. If they are not, the query can be stopped. We won’t explore testing in this article, but it is still useful to explore.

Using Components in an Example
For our example, we’ll take a simple insert statement and demonstrate how it translates into a Matillion transformation job. Suppose we have the following insert statement:
INSERT INTO orders_by_city
SELECT
o.id as order_id,
o.date as order_date,
o.invoice_no as invoice_number,
o.usd_amount as usd_amount,
c.name as city_name
FROM orders o
JOIN cities c
ON o.city_id = c.id
WHERE date >= '2023-04-05'
In order to transform this statement into a Matillion ETL transformation job, we just have to put together a few components to reach the final outcome, which will look like this.

Step 1 – Source Inputs

For our example, our data will come from two table inputs for “cities” and “orders”. Let’s look at the settings for the Table Input in greater detail:
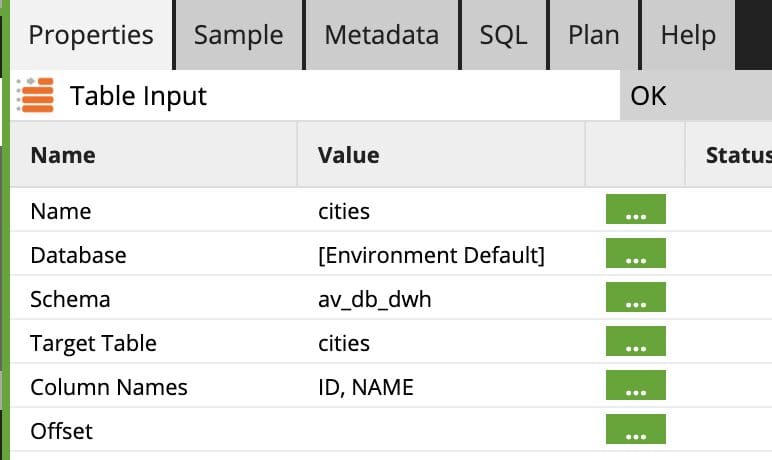
- Name: Name of the component.
- Database: Source Database of the table. This can either be a hardcoded database name, a variable, or “Environment Default,” which is an environment variable that can be configured beforehand.
- Schema: Source schema of the table. This can either be a hardcoded schema name, a variable, or “[Environment Default],” which is an environment variable that can be configured beforehand.
- Target Table: The source table.
- Column Names: The columns being read into this component.
- Offset: A specific component for the Snowflake Data Cloud’s Time Travel feature. This “offsets” the source table contents by a number of specified seconds, which allows a user to see a table as it was X seconds ago. We don’t have that for this example.
Step 2 – Filters
The filter component has the following menu options to be selected:

- Name: The name of the component.
- Filter Conditions: Within this menu are several selections.

- Input Column: The column you want to filter on.
- Qualifier: Whether you want the filter to look for records that qualify or do not qualify. Imagine this as the “=” or “!=” portion of a statement.
- Comparator: The filter condition you want to implement. Some of these are meant for numeric or date values. Others are meant for text-type filtering.
- Value: The value being compared.
You can also toggle the number of filters being implemented with the + and – buttons in the bottom left corner.
Step 3 – Joins

For the join component, there are a few menu inputs that need to be filled out in order for the component to validate successfully.

- Name: This is the name of your component. A best practice here is to give the component a readable name or, better yet, a naming convention such as “JOIN_Order_City” or “LJOIN_Order_City.”
- Main Table: Imagine this being the table in your SQL query that directly follows the “FROM” clause. In our case, this table is “orders.” Main Table Alias: Imagine this being the alias you give your table that directly follows your “FROM” statement. In this case, it would be “o.”
- JOINS: In this section, you will define your joined tables. Here you can define one or many tables to join to your main table, the joined table alias(es), and the type of joins. This would equate to the portion of the query where your JOIN statement is. You have the ability to add more tables to the join condition as well as use grid variables in place of tables.

- JOIN Expressions: In this section, you define the join conditions for each table. This is fairly straightforward. It will be the same syntax as the join condition in your SQL query.
- Output Columns: In this section, you define the output from the join component. These are the columns defined in the SELECT portion of your SQL statement. It also allows you to define column aliases as well.

Step 4 – Output

For our example, we’re going to perform a table output. There are a number of menu selections for this component.

- Name: he component table.
- Warehouse: The name of the warehouse responsible for running the job.
- Database: The database being pointed at.
- Schema: The schema being pointed at.
*Note: For the Warehouse, Database, and Schema, you can also choose the setting “Environment Default,” which will default to an Environment level setting that can be managed in a different portion of the application.
- Target Table: This is the table being written to.
- Fix Data Type Mismatches: A boolean that can be toggled to attempt to cast mismatched data to the required target type. Default is no.
- Column Mapping: This is where you will map the fields from the source component, in this case our “order-city join” to our target table.
- Order By: If we were going to sort our output in a specific order, we can define that order here.
- Truncate: This field defines whether our data is going to be appended to the target table or if the table will be truncated, then reloaded.
Closing
With this blog, we have seen a simple example of how a SQL script can be transformed into a Matillion Job. We also saw a small sample of the many features and configurations that are possible within a Matillion transformation job.
Looking for more Matillion assistance? phData excels at assisting organizations in achieving success with Matillion. Contact us today for help, advice, and actionable strategies.









