

This blog will demonstrate that seemingly smart architectural choices made without fully understanding the tech and long-term impact can make things more complex than needed.
We’ll examine a real example with AWS SageMaker, Lambda, and API Gateway, and explain how shifting your thinking from just being wise to being shrewd and practical can seriously boost your cost savings, performance, and code ease of maintenance.
In this blog, you’ll learn how your team can avoid common traps when building awesome software.
The Initial Challenge: Deploying a SageMaker Endpoint with a REST Interface
We kicked things off with a simple goal: get an AWS SageMaker model endpoint up and running, accessible via a good old REST HTTP interface. Not entirely sure where to begin, we naturally consulted Google for some pointers.
The Stack Overflow link, while not a direct solution, points to an accepted answer suggesting the Sagemaker runtime client. But that’s a no-go for us, as the client won’t necessarily be tied to AWS. We need an HTTP API interface.
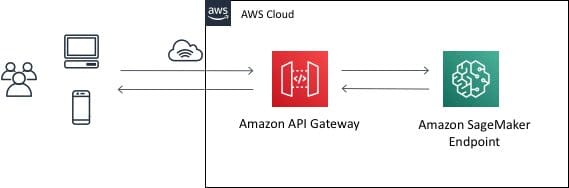
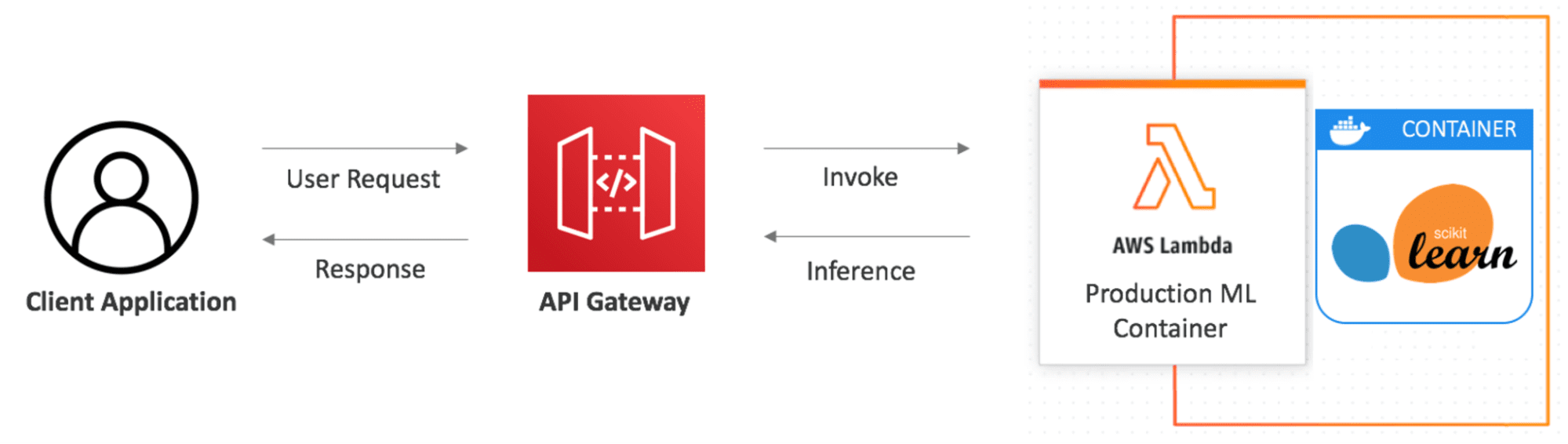
The second link is an AWS blog post, published on July 19, 2018, called Call an Amazon SageMaker model endpoint using Amazon API Gateway and AWS Lambda. It offers an interesting overview of the AWS SageMaker endpoint service, as presented in the diagram below:
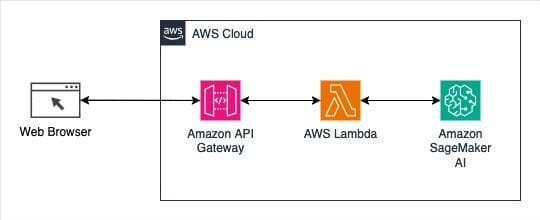
The architecture diagram illustrates a robust design, seamlessly integrating Amazon API Gateway, AWS Lambda, and Amazon SageMaker AI. AWS Lambda adeptly acts as an intermediary, establishing the crucial REST HTTP interface between API Gateway and SageMaker, thereby simplifying API Gateway integrations.
So, we hit another internal snag: our ML job isn’t just a single Machine Learning model inference. We’ve got four models split across two business areas. That sent us Googling “multimodel endpoint AWS Sagemaker”, and instead of another blog, we actually found official AWS docs on “Multi-model endpoints.” Sweet!
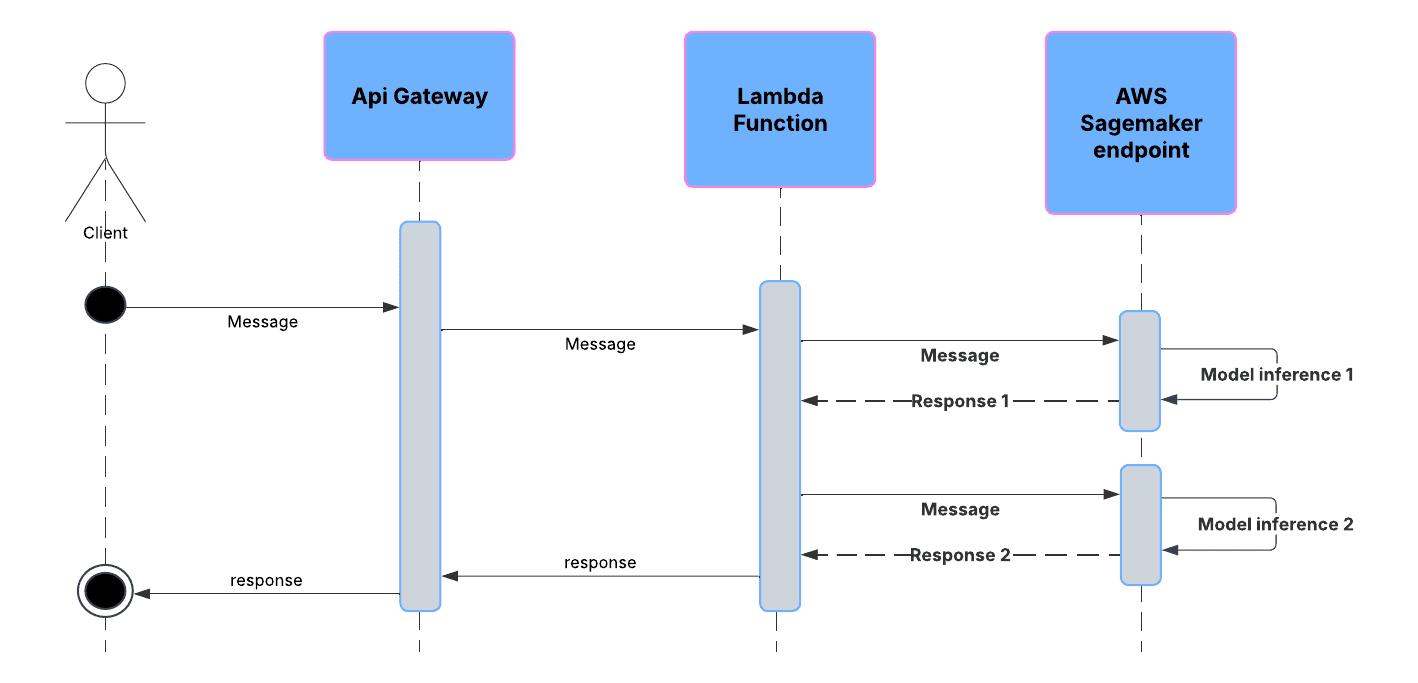
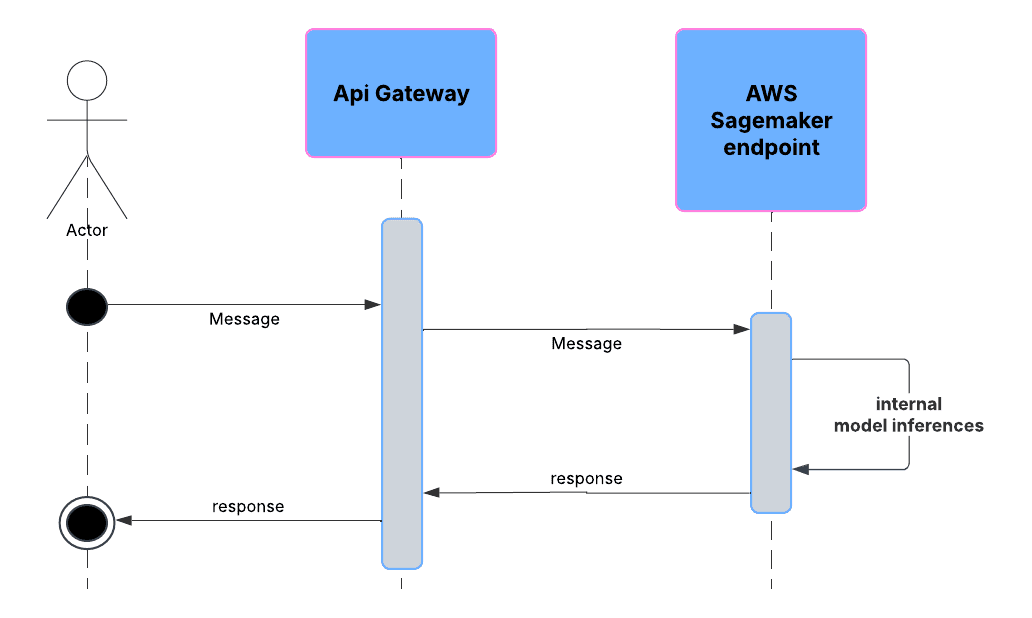
Following the multi-model endpoint approach, we will now create an endpoint that is able to serve different machine learning models. And we access their predictions by identifying which model we want to use in the payload. This increases the importance of the intermediary lambda. Why? Because our code has to make multiple calls to an AWS SageMaker multi-model endpoint. That brings us to this sequential system diagram:
Unforeseen Consequences: When "Good Enough" Isn't Good Enough
For maintainability, this architecture divides system logic into a Lambda function and an AWS SageMaker endpoint. Initial deployment was straightforward, but subsequent updates became complex due to the 24/7 operation, which prevented system downtime. Our solution involved integrating feature flags and closely linked deployments to ensure continuous operation without interruption.
Our system is humming along nicely, with clients using it exactly as we hoped. Performance is looking great! But if we peek under the hood, there’s a little snag: all requests go through a single-file line, hitting every model one after the other.
This means a couple of back-and-forths between a Lambda function and our AWS SageMaker endpoint for every client. Even with that, the system is super speedy, averaging 0.6 seconds response time – way under our 1-second goal. We thought at least.
Aside from how fast it is, Lambda brings up two big questions: how it handles multiple requests at once and how much it costs.
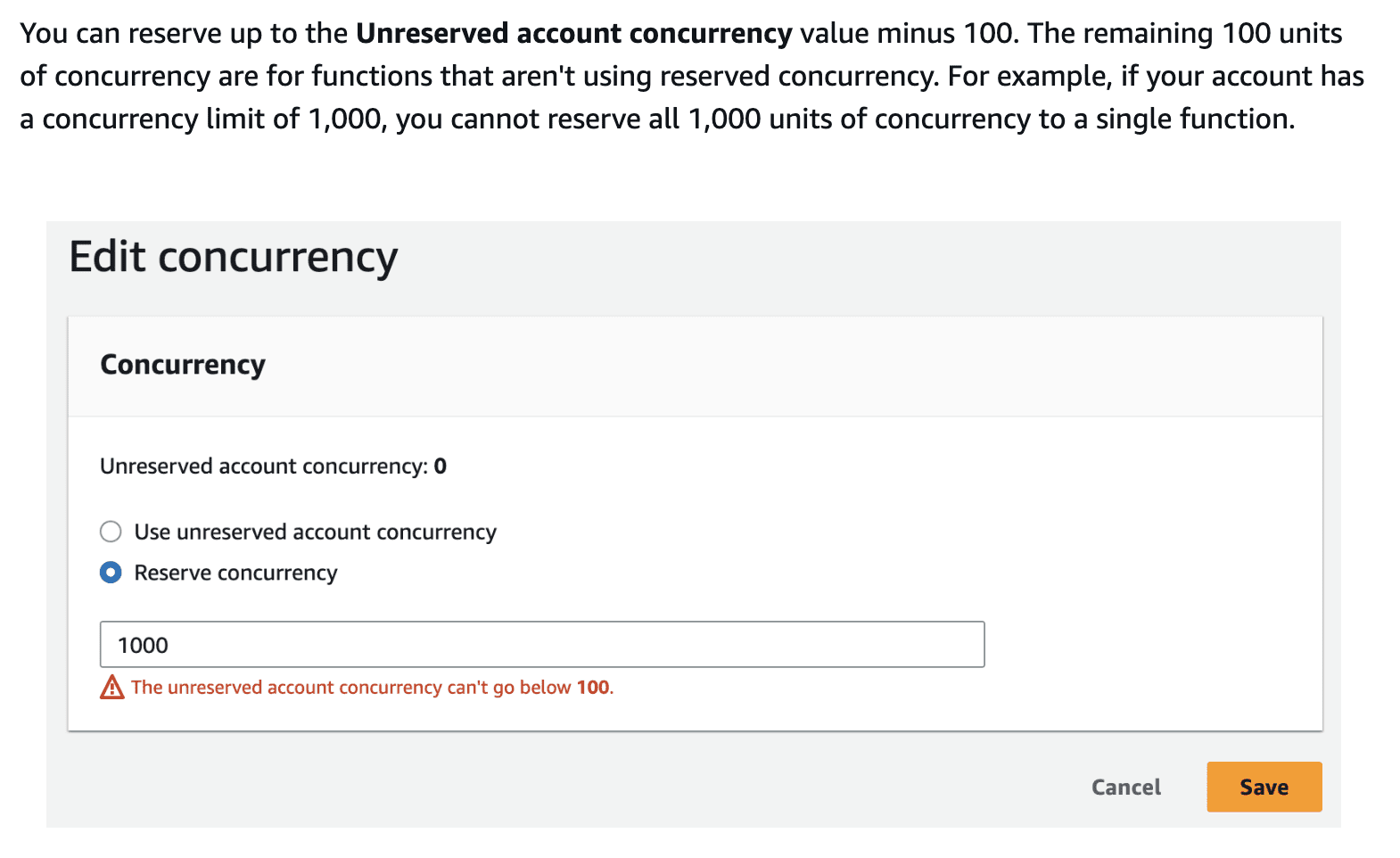
To handle multiple requests, Lambda has a configuration called (reserved or unreserved) concurrency. Lambda functions, by default, share an unreserved pool of 1000 simultaneous executions in an AWS account. In our shared AWS account, which is home to tons of other teams and well over 1000 Lambda functions, if every function got just one request per second, we’d run out of capacity fast.
This inherent limit caused some infrequent but worrying errors, where our system just couldn’t respond. To keep things smooth and reliable, we set a concurrency level that can handle the traffic we expect.
So, about cost strategy, Lambda charges us based on how many requests we make and how long the function runs per GB-second. Even though it might seem like a small piece of the pie, we felt it was worth a look.
Our Lambda function is pretty simple: it takes some data, makes two requests, combines the answers, and then sends them back. But even with simple code and tiny data payloads (under 30KB), we noticed our memory usage was pretty high, and our Python Docker image size was around 550MB.
Our investigation revealed that Pandas was a significant contributor to memory consumption. While excellent for data manipulation in Python, Pandas and its dependencies can consume considerable memory, upwards of 160MB. We calculated that our unoptimized code used approximately 18,333 times more memory than the actual data size (550MB vs. 30KB). So we are paying much more to transaction code than the actual data that we actually want to transact.
Discovering "Another Way": Finding More Savings
In a March 13, 2020, AWS blog post, Mike Rizzo suggested a different method for creating a machine learning-powered REST API using Amazon API Gateway mapping templates and Amazon SageMaker. This post presents a simpler architecture that, even though it needs more advanced Amazon API Gateway setup, ultimately makes more sense.
We’ve simplified the architecture by ditching the lambda function. Turns out, our ML pipeline works great even without a multi-model endpoint, which we initially thought was a must-have. Plus, this new approach makes the sequential diagram way clearer!
Deployment was way easier thanks to AWS SageMaker’s endpoint deployment strategies. They’re perfect for keeping things running smoothly with zero downtime. Even though we needed a more advanced usage with blue green deployments and setting up alerts, SageMaker totally handled it.
Plus, we saw a huge boost in performance, especially with throughput and latency. I believe a big part of this improvement is because we cut out two separate HTTP requests between different AWS services. We’ll show you in the next section.
The Proof is in the Pudding: Load Test Results and Throughput Enhancement
We used the Locust library to implement a load test scenario, which was straightforward to set up, and successfully validated our architectural changes. Although conducted with varying resources, leading to different requests per second (RPS) results, we were able to extract valuable benchmarking metrics.
In the initial architecture, inspired by a July 19, 2018, AWS blog post, our load test achieved 617.68 RPS. Over a 10-minute test, a total of 370,870 requests were made, with 260,464 (70.23%) failing. Our throughput breaking point was identified at approximately 180 RPS.
Response times were less than 4 seconds at the 95th percentile and under 0.860 seconds at the 50th percentile. This performance was suboptimal, approaching our 1-second requirement limit and exhibiting a 95th percentile latency under stress four times higher.
For the second architecture, guided by a March 13, 2020 AWS blog post, a new load test was conducted. We reached approximately 886.83 RPS. During the 10-minute test, 532,250 requests were made, with 373,839 (70.24%) failing. Response times stayed under 2 seconds at the 95th percentile and under 0.3 seconds at the 50th percentile.
Metric / Architecture | Initial Architecture | Cost-saving Architecture | Performance Enhancement |
|---|---|---|---|
Requests Per Second (RPS) Achieved | 617.68 | 886.83 | 43.56% increase |
Total Requests (10-minute test) | 370,870 | 532,250 | 43.56% increase |
Failed Requests (%) | 70.23% (260,464) | 70.24% (373,839) | Minimal change |
Throughput Breaking Point | ~180 RPS | Significantly Higher (not explicitly stated, but implied by higher RPS achieved) | Substantial increase (implied) |
95th Percentile Response Time | < 4 seconds | < 2 seconds | 50% reduction |
50th Percentile Response Time | < 0.860 seconds | < 0.3 seconds | ~65% reduction |
Latency | Suboptimal, approaching 1-second requirement limit | Significantly improved | >4x improvement (implied by 95th percentile reduction) |
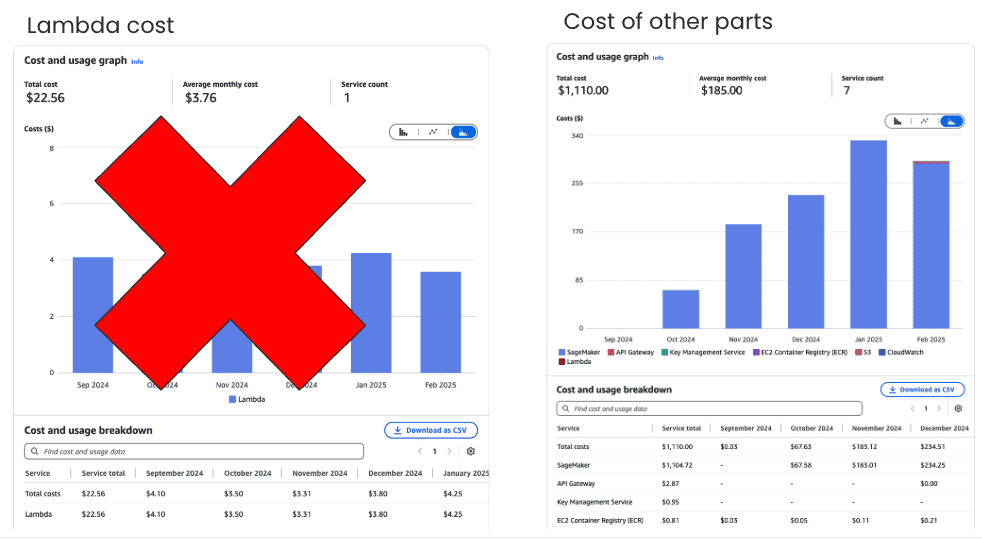
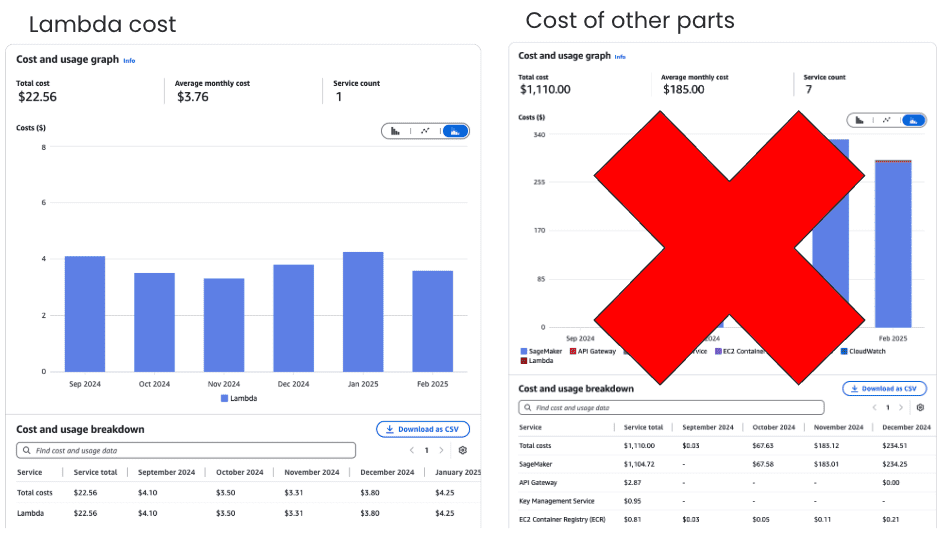
So, about the expenses, the Lambda function hardly costs anything – like $3.76 a month – and we’ve since gotten rid of that. Most of our spending, around $185 a month, was on Amazon API Gateway and AWS SageMaker endpoint.
Can We Find Even Another Way?
We questioned whether an AWS SageMaker endpoint was truly essential for our optimization goals. Since our ML model files were tiny and used very little memory, we explored a different approach: having the AWS Lambda function handle the inference logic directly as the backend.
An AWS blog post from June 22, 2021, on “Deploying machine learning models with serverless templates“, really helped us out.
The Lambda-only setup was a game-changer, really boosting speed, handling more requests, and best of all, cutting costs way down. Ditching the separate SageMaker endpoint made everything so much smoother. This whole process really hammered home how important it is to keep evaluating and tweaking our solutions to fit the specific needs, instead of just sticking to the original plan.
Below, you’ll see the load test results that show just how much better this optimized approach performed.
We ran a new load test for 10 minutes, hitting about 910 requests per second and totalling 526,185 requests. Only a tiny 5 (0.00%) of those failed due to throttling. And get this, response times stayed under 2 seconds (95th percentile) and under 0.460 seconds (50th percentile) the whole time!
This new implementation brought some serious upgrades:
Breaking Point: We jumped to over 900 requests/second (from around 250 previously).
Response Time Impact: Consistently under 2 seconds (95th percentile) for most tests, with only occasional jumps to 5 seconds due to Lambda refresh (which is a huge improvement from nearly 25 seconds under stress in the old version).
Cost of infrastructure: On top of all that, this solution slashed costs big time, now just 3.76 USD/month plus a bit extra for Amazon API Gateway. That’s a whopping 98.5% reduction from the original cost!
The new architecture offers better speed, no obvious breaking point for throughput, and all the great deployment, maintenance, and monitoring features that come with using Lambda.
Lessons Learned: Becoming Cloud Savvy
“An hour of work can save a minute of planning.”
Reflecting on this experience, it’s clear that careful resource management goes beyond just cost. Factors like services, integrations, vendor lock-in, and maintainability can significantly impact daily operations. The often-overlooked “cognitive load” also carries a hidden cost, and a stable, working system might demand far less effort than initially perceived.
The internet offers a wealth of information, but official documentation, while sometimes excellent, isn’t always crafted by technical experts. This can lead to suboptimal systems in terms of ease of maintenance, process, support, or cost. Therefore, consume information judiciously. While the pressure to “build, build, build” is real, building without forethought can hinder future development capabilities, as highlighted by Martin Fowler’s Design Stamina Hypothesis.
Systems are in constant flux, and leveraging this change to our advantage is key. My experience refactoring countless systems and thousands of lines of code has instilled in me a deep appreciation for simplicity and peace of mind, all while meeting business requirements.
Here are the key takeaways from this journey:
Beyond the Obvious: It’s crucial to look past initial, seemingly “simple” solutions and thoroughly evaluate alternatives.
Questioning Assumptions: Readers should be encouraged to scrutinize assumptions and delve deeper into documentation and best practices relevant to their specific use cases.
The Value of Optimization: Optimization extends beyond mere cost reduction; it’s about enhancing stability, maintainability, and the overall health of the system and the team.
Conclusion: Embracing Shrewdness in Cloud Architecture
Ultimately, being truly savvy in cloud architecture means cultivating the perception and shrewdness to make practical decisions that optimize for long-term success. By applying these lessons, looking beyond the obvious, questioning assumptions, and valuing holistic optimization, you can build more efficient, robust, and cost-effective systems that truly stand the test of time.

Ready to put these strategies into action?
Connect with phData to see how our experts can help guide your cloud journey.









