

As data volumes continue to grow, the demand for scalable and low-maintenance data infrastructure grows with it. Teams want fast access to reliable data and to be able to build pipelines for new sources quickly and efficiently without worrying about things like schema drift. That’s where Fivetran and Apache Iceberg come in.
In this blog, we’ll explain what Fivetran and Iceberg tables are, how the combination of the two is a powerful tool in data, and where using the two of them together can make a huge impact on your data platform.
What is Fivetran?
Fivetran is a data integration system used to simplify the ingestion of many data sources into a data warehouse or data lake. Instead of data engineers spending time building connections and data pipelines using code-based solutions, Fivetran automates the entire extract and load process, with minimal configuration by users. It offers many pre-built connectors for systems like Salesforce, Snowflake, Google Analytics, and more.
This ensures your data stays fresh with just a few clicks for setup. With automated schema management, error handling, and incremental updates, Fivetran lets data teams focus on delivering insights rather than managing infrastructure.
What are Apache Iceberg Tables?
Apache Iceberg is an open source table format built to handle large-scale analytics datasets in data lakes. Unlike traditional table formats that can struggle with performance, schema change, and managing large amounts of data, Iceberg can handle these problems by separating metadata from the underlying data files.
This makes operations faster and more scalable. It supports ACID transactions, time travel, and schema evolution, letting you update or rollback datasets without worrying about breaking pipelines. Plus, Iceberg integrates with engines like Spark, Trino, and Flink, making it flexible enough to fit a range of analytics architectures.
Iceberg’s metadata-driven design performs query optimization at scale, skipping irrelevant files and dramatically improving performance. Snapshot isolation and rollback capabilities add a layer of reliability and governance that’s very often missing from traditional data lakes.
Schema evolution is also straightforward, as new columns can be added or removed without disrupting existing pipelines. Time travel allows you to query historical versions of your data, which is great for auditing or reproducing analyses. Iceberg tables combine the flexibility of a data lake with the stability of a warehouse, which is proving to be a go-to solution for modern analytics teams.
Why use Fivetran with Iceberg Tables?
Benefits
Pairing Fivetran with Iceberg gets you a streamlined, fully managed pipeline that takes care of heavy lifting. Fivetran handles the extraction and loading from a wide variety of sources for your Iceberg tables without the need for custom scripts or manual maintenance. That means your tables are always fresh and ready for analysis.
The real magic happens when Fivetran’s incremental updates meet Iceberg’s snapshot-based architecture. ACID transactions, schema evolution, and time travel features work hand-in-hand with Fivetran, letting you track changes, query historical data, and even roll back mistakes with confidence. For teams building cloud-native data platforms or modern data lakes, this combo isn’t just convenient, it’s transformative. It accelerates data availability, ensures reliability at scale, and simplifies governance, all while freeing analysts and engineers to focus on insights rather than infrastructure.
Iceberg Architecture Complexities
With Iceberg, each table is constructed of a hierarchy of metadata and data files, allowing query engines to quickly restore a table to any point in time and perform complex queries with warehouse speeds. Historically, ingesting source system data into Iceberg format has been one of the largest hurdles to Lakehouse adoption, requiring advanced developer skills in Python or Spark and a willingness to build and maintain numerous custom pipelines. Oftentimes, teams don’t possess the necessary skills, and there are understandable reservations about creating and maintaining a whole new custom piece of architecture. This is where Fivetran’s fully managed Iceberg destination will simplify the complex ingestion process.
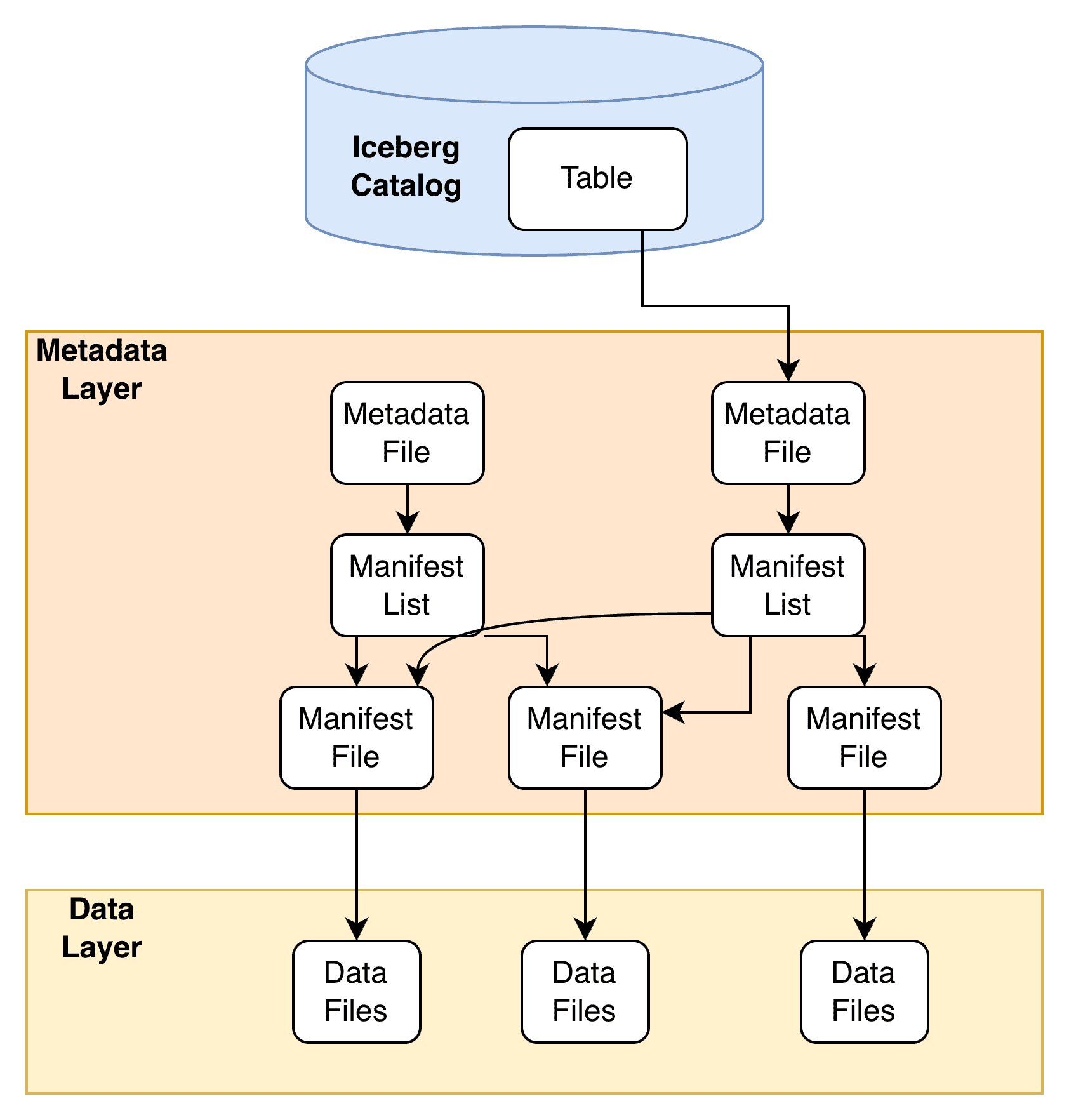
Other Considerations
Utilizing Fivetran with Iceberg tables introduces a few important considerations for clients. One key decision is which catalog to use for managing ingested data. Fivetran Polaris provides flexibility by exposing data through a REST API, making it accessible to all major catalogs. AWS Glue, on the other hand, allows Glue crawlers to treat the tables as first-class objects for broader AWS ecosystem compatibility. For organizations running on Databricks, Unity Catalog offers a natural fit—making the Fivetran Lakehouse an especially compelling solution in that environment. Additionally, because raw data is now exposed in a lake, clients must implement a strong security model around that data. In Snowflake environments, this may mean managing an extra security layer, whereas Databricks users can leverage Unity Catalog’s built-in governance for streamlined protection.
Iceberg Datalake Services
Fivetran Managed Data Lake Service
For Iceberg, Fivetran does more than just load data into tables. Fivetran’s Managed Data Lake Service is an end-to-end, fully automated way to build and operate an open data lake without requiring customers to manage infrastructure, pipelines, or table optimization. Instead of configuring Spark jobs or ingestion frameworks, users can simply select their data sources and destinations. Fivetran then delivers data directly into an Apache Iceberg–based lake, handling schema evolution, partitioning, compaction, retention policies, and performance tuning automatically. This eliminates the operational burden of running a data lake while keeping the openness and interoperability of Iceberg.
The service is designed to give companies lakehouse flexibility with warehouse-like simplicity. Because the data is stored in Iceberg tables on cloud object storage, it can be queried by a wide range of engines, like Snowflake, Databricks, BigQuery, and Athena.
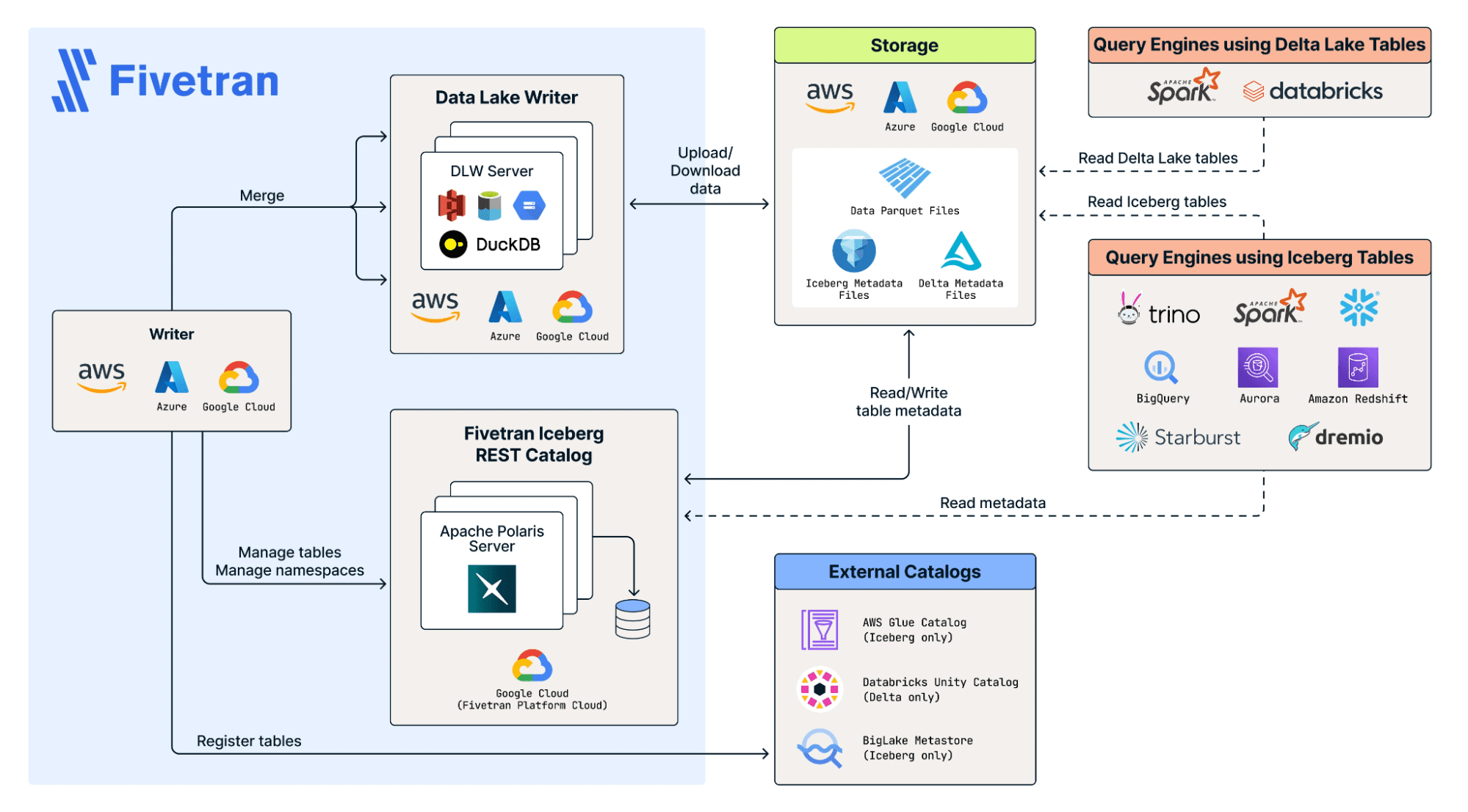
Snowflake Catalog Linked Databases
Snowflake makes it even easier to integrate an external Iceberg catalog (such as Fivetran’s). With Snowflake’s catalog-linked database for Iceberg, you can query and operate on Iceberg tables as if they were native objects in Snowflake, with very little engineering effort. By linking to an external catalog, Snowflake can read Iceberg metadata, understand schema and partitions, and access the underlying files without having to ingest or transform the data. That means teams can leverage Snowflake’s performance engine, governance features, and SQL capabilities on top of an open data lake or lakehouse to get the best of both worlds.
Use Cases
Machine Learning and Data Science
As the saying goes, garbage in – garbage out when it comes to machine learning models and AI. The models are only as good as the data being fed into them. That’s where leveraging Fivetran and Iceberg becomes a solid combination. With schema evolution, data scientists can easily incorporate new features over time without breaking existing pipelines or model training jobs. Its time travel feature also enables reproducibility: you can re-train a model on the exact dataset version used weeks or months earlier, which is essential for auditability and debugging.
Multi-source Consolidation
Normally, bringing CRM, ERP, marketing tools, and web analytics all into one place is a feat of data engineering, but not with Iceberg and Fivetran. Iceberg is built for large amounts of data, and Fivetran has easy-to-use connectors for hundreds of different sources, making the combination ideal for consolidating data into one catalog. This allows for faster and easier analytic insights when all data is combined into a central data platform.
Regulatory Compliance and Auditing
Compliance and auditing are becoming challenging with the amount of data that organizations are maintaining. Industries like finance and healthcare have strict compliance policies that are hard to follow with traditional databases and code-based ingestion software. Using Fivetran’s reliable ingestion capabilities along with time travel queries and snapshots in Iceberg, they provide a full record of data changes. These can be used to audit the data quickly and reliably without much effort by data teams.
Best Practices
- Use incremental loads whenever possible: Since Iceberg’s snapshot-based design handles incremental loads so well, configure Fivetran loads to be incremental syncs instead of full reloads to ensure your data stays fresh without unnecessary compute overhead.
- Enable schema change: Since both Fivetran and Iceberg handle schema change, enable schema change handling settings to allow Fivetran to add new columns or change column data types automatically.
- Optimize File Sizes and Compaction: Since Fivetran’s incremental loads can create many data files, which can degrade performance if left unmanaged, it’s recommended to periodically run Iceberg’s compaction job to merge smaller files into optimal sizes.
Closing
Fivetran and Iceberg are a natural fit for companies looking to modernize their data platform without adding complexity. This is a great option to explore for customers looking to reduce ingestion costs or land data in almost every query engine. Fivetran gets rid of the burden of building and maintaining custom data pipelines, while Iceberg provides the scalability and reliability needed to manage your data.
Together, they provide a foundation for analytics and machine learning. By combining automated ingestion with a high-performance table format, teams can move faster and focus on generating insights instead of maintaining pipelines.

Ready to architect your next‑gen lakehouse with Fivetran + Iceberg?
phData’s experts can help you assess fit, design a scalable ingestion strategy, and navigate catalog, governance, and cost trade-offs—so you move from concept to production with confidence.









