

In environments with high data volumes, performing operations such as bulk inserts, complex transformations, or analytical tasks sequentially often leads to inefficiencies. Most operations are designed to run sequentially due to process design or technical limitations. This applies to both batch and near real-time processing.
However, there will always be cases where it’s possible to redesign processes to execute steps asynchronously.
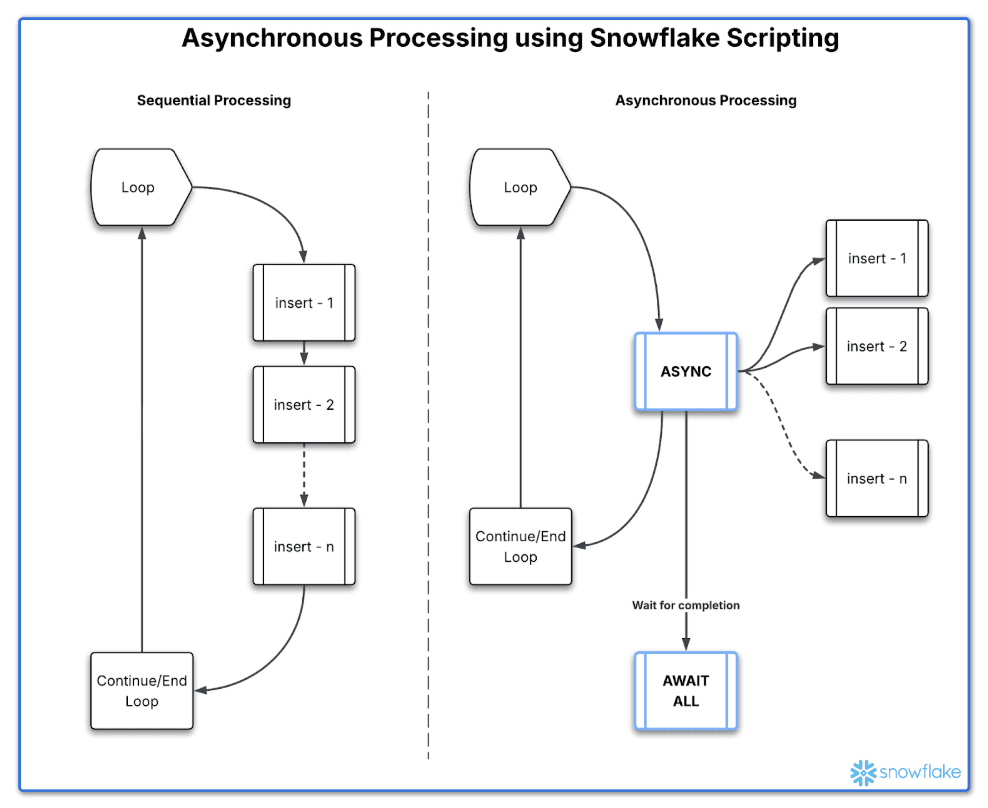
Asynchronous processing allows tasks to run independently without waiting for previous tasks to complete, improving efficiency and performance. Snowflake Scripting previously had limitations where parallel processing wasn’t possible without a custom design.
This often resulted in underutilization of resources or failure to meet defined SLAs. Some of the use cases in business could be:
Splitting incoming data into multiple chunks/partitions and executing them asynchronously.
Grouping business logic and modularizing it into separate stored procedures that can be called asynchronously.
In a near real-time process, isolating non-essential steps like logging/notifications as separate processes and triggering them asynchronously to meet defined SLAs.
In this blog, we will examine how asynchronous processing can parallelize multiple operations instead of running them sequentially.
What is Asynchronous Processing, and Why Does it Matter?
When working with traditional stored procedures, SQL statements typically execute sequentially; each command must wait for the previous one to finish. This is fine for small, quick tasks, but in data-intensive environments, it quickly becomes a bottleneck:
When queries are executed sequentially, several inefficiencies arise:
Increased Execution Times: Each query must finish before the next one starts, extending the overall processing duration.
Underutilized System Resources: Only a single thread of work is active at any given time, leading to inefficient use of available system resources.
Optimization Challenges: Optimizing workloads, especially those involving large data transformations or concurrent queries, becomes complex due to the synchronous nature of processing.
Imagine you’re building an ETL application that fetches data from multiple time periods or customer segments. Running these queries sequentially would be painfully slow.
That’s where asynchronous execution comes in.
Asynchronous child jobs in Snowflake allow you to initiate multiple SQL statements that run in parallel, or in the background. These jobs don’t block the procedure’s progress, giving you greater control over execution flow and enabling higher throughput.
When to Use Asynchronous Processing in Snowflake
Asynchronous child jobs are powerful features that can be used in various ways in Snowflake. Some practical use cases include:
Concurrent Table Inserts/Updates: Execute multiple insert/update statements in a loop, targeting specific records or composite keys without blocking each other.
Data Validation Checks: Run concurrent statements to perform various custom data validation checks in parallel. These checks can be simple SQL statements or stored procedures.
Logging and Monitoring: Trigger concurrent statements to independently log different metrics and status updates or send updates to various systems (using Snowflake external access).
Multi-Table Inserts: While Snowflake supports multi-table inserts, the source typically needs to be the same. With asynchronous features, multi-table insertions can be implemented with different granularities and transformation logic.
Let’s look at a simple example of implementing an asynchronous process in Snowflake Stored Procedures and compare the performance between sequential and asynchronous execution. For this testing, we will use Snowflake’s sample TPCH data and prepare sample tables with only the required columns.
Use the following statements to create sample data and insert it into the source table.
CREATE OR REPLACE TABLE TPCH_TGT_ORDERS (
ORDERKEY NUMBER,
ORDERDATE DATE,
TOT_PRICE NUMBER(12,2)
);
CREATE OR REPLACE TABLE TPCH_SRC_ORDERS (
O_ORDERKEY NUMBER,
O_ORDERDATE DATE,
O_TOTALPRICE NUMBER(12,2),
O_COMMENT VARCHAR
);
INSERT INTO TPCH_SRC_ORDERS
SELECT O_ORDERKEY, O_ORDERDATE, O_TOTALPRICE, O_COMMENT FROM SAMPLE_DATA.TPCH_SF10.ORDERS ;
Next, let’s create the following stored procedure to asynchronously insert data into the target table. Note the two keywords below:
ASYNC: This keyword asynchronously submits the statement in the backend for processing.
AWAIT ALL: This keyword waits for all asynchronously submitted statements to finish.
CREATE OR REPLACE PROCEDURE CALC_PRICE_30_DAYS(INPUT_DATE DATE)
RETURNS STRING
LANGUAGE SQL
EXECUTE AS CALLER
AS
DECLARE
total INTEGER DEFAULT 0;
maximum_lookback INTEGER DEFAULT 30;
given_date DATE DEFAULT INPUT_DATE;
BEGIN
FOR i IN 0 TO maximum_lookback DO
LET lookback_day INTEGER := i;
--async keyword ensures that insert statement will be fired asynchronously
ASYNC (
INSERT INTO TPCH_TGT_ORDERS (ORDERDATE,ORDERKEY,TOT_PRICE)
SELECT O_ORDERDATE, O_ORDERKEY, SUM(O_TOTALPRICE)
FROM TPCH_SRC_ORDERS
WHERE O_ORDERDATE = :given_date - :lookback_day
GROUP BY ALL
);
END FOR;
-- Awais statement ensures all insertions finish before returning ---
AWAIT ALL;
RETURN 'Completed';
END;
CALL CALC_PRICE_30_DAYS('1998-08-02');
The entire procedure took around 2.5 seconds to complete in an XS warehouse.
Now, let’s change the code slightly to remove the ASYNC and AWAIT ALL logic and rerun the procedure. The same procedure now takes around 18-19 seconds to complete in an XS warehouse. There is about a 9-fold improvement when using asynchronous processing in Snowflake Scripting.
CREATE OR REPLACE PROCEDURE CALC_PRICE_30_DAYS_NO_ASYNC(INPUT_DATE DATE)
RETURNS STRING
LANGUAGE SQL
EXECUTE AS CALLER
AS
DECLARE
total INTEGER DEFAULT 0;
maximum_lookback INTEGER DEFAULT 30;
given_date DATE DEFAULT INPUT_DATE;
BEGIN
TRUNCATE TABLE TPCH_TGT_ORDERS;
FOR i IN 0 TO maximum_lookback DO
LET lookback_day INTEGER := i;
--async statement removed and insert statement is fired sequentially.
INSERT INTO TPCH_TGT_ORDERS (ORDERDATE,ORDERKEY,TOT_PRICE)
SELECT O_ORDERDATE, O_ORDERKEY, SUM(O_TOTALPRICE)
FROM TPCH_SRC_ORDERS
WHERE O_ORDERDATE = :given_date - :lookback_day
GROUP BY ALL
;
END FOR;
RETURN 'Completed';
END;
CALL CALC_PRICE_30_DAYS_NO_ASYNC('1998-08-02');
Best Practices for Optimizing Asynchronous Child Jobs in Snowflake
Here are some strategies for optimizing asynchronous processing as well as tips to get the most out of asynchronous child jobs:
Group similar tasks: Combine related jobs and wait for their collective completion.
Manage concurrency: Limit the number of concurrent asynchronous statements, especially with large datasets, to avoid overwhelming the warehouse and ensure efficient performance.
Track performance: Monitor the execution time and outcomes (success/failure) of child jobs to inform future optimizations.
Modularize complex jobs: Break down intricate jobs into smaller, independent stored procedures that can be executed asynchronously.
Closing
Snowflake’s asynchronous child jobs unlock powerful potential for developing quicker and more effective stored procedures.
This capability facilitates genuine parallelism in your operations, whether they involve data ingestion, transformation, or analytics. By moving past sequential execution, you can shorten runtime, boost scalability, and fully leverage Snowflake’s adaptable compute resources.
If your organization needs help setting up high-performing data engineering pipelines, please contact phData to learn more about how our data migrations and Snowflake consulting services can help.

Build High-Performance Data Engineering Pipelines Fast
Leverage phData’s expert Snowflake consulting and end-to-end data migrations to design, deploy, and scale reliable pipelines.









