

I wrote a data-munging app the other day. Of course, when I say I wrote,
I mean Claude wrote it. It was the nth iteration of Adventures in Pure Agentic Coding, where human intervention is at a high level, offering perspective and desire, but letting AI articulate the details, and execute on its own plan.
I remember talking to our SVP of product engineering over dinner last June about building software that lets you never write a line of code again. Purely fanciful at the time. Vibe-coding existed. AI was not so bad at code, but never capable of building project-sized, repo-sized applications successfully.
Today, the technology is there. I wanted to use this blog to talk a bit about the technology and techniques that got us here, and about a philosophical shift underway in how people see software.
So, back to that data-munging app. I wrote it for my mom, who works as a graduate student coordinator at a university. A lot of her role boils down to combining and understanding data.
Who did we reach out to about applying?
Who got back to us?
Who did we send packets to?
All in Excel.
Why? Because modern data tools are expensive, and the operational burden of onboarding, maintaining, training, etc, of the platform is just too high. Central IT at universities exists, but they’re too busy convincing freshman not to wash their laptop with soap and water. That gets us back to the title of this blog.
There was a reason this software would never be written. It would have taken me, or anyone, a really long time to write a JavaScript app that pulls in the data, offers identity resolution capabilities, join logic—all in a friendly GUI.
In fact, this has been done before, and the folks who have done it would like to be paid. Fair enough. Except now, the barrier to entry for useful software has been nearly flattened. While a lot of attention is paid to how AI can accelerate the development of large legacy systems (that most of us practitioners work on every day), AI-driven development radically opens the door to all the software that has never been written. We need to talk about it.
Spec-Driven Development is a Major Velocity Unlock
Spec-Driven Development is the pattern that makes this whole thing work. Instead of starting with files and frameworks, you start with a spec: a natural language description of what the software should do, who it’s for, and the constraints that matter. No UML, no DSL, just clear writing.
While specific flows differ slightly, at a high level, agents walk through a simple loop:
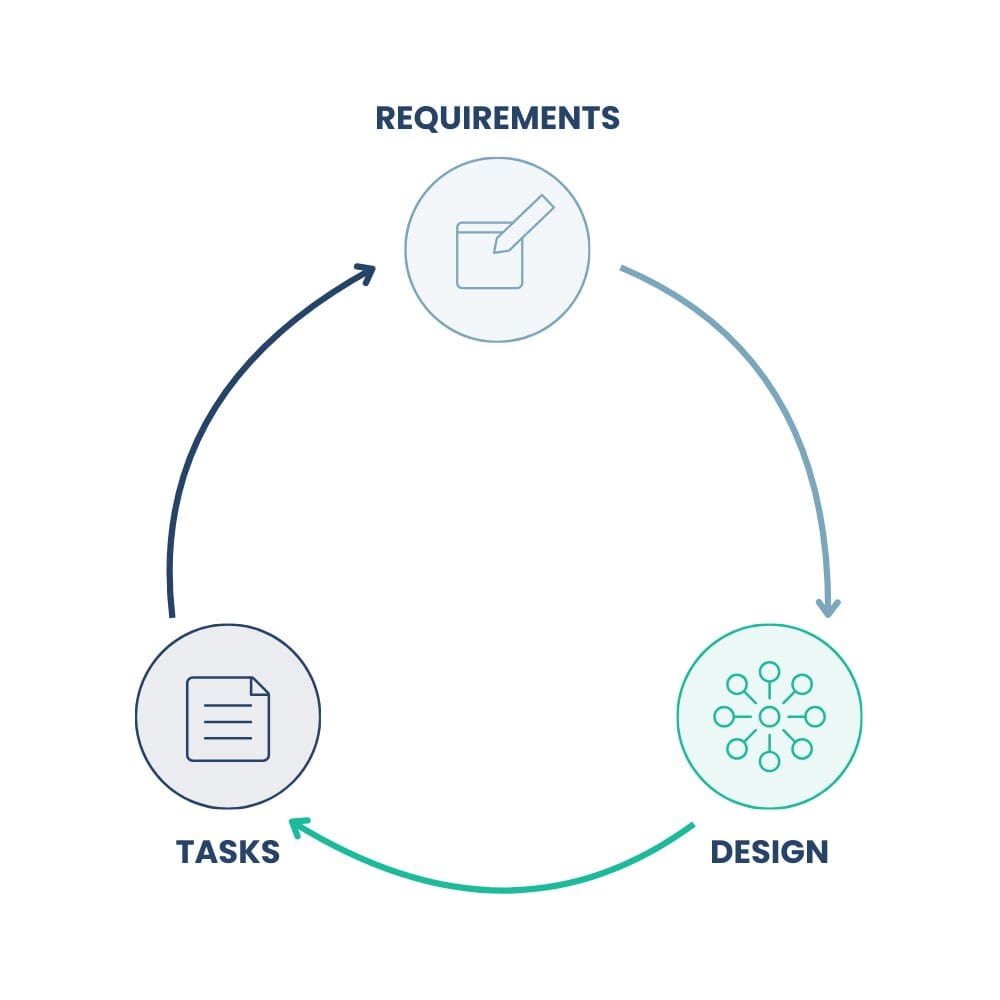
The spec becomes a design: APIs, data models, UX flows, and deployment shape. The design becomes an executable plan: concrete tasks, code changes, migrations, tests. At each step, the artifacts stay human-readable, so you can review, edit, and version them the same way you’d treat code.
The magic is that you don’t have to drop down into implementation every time you want to change something. You update the spec or the design, regenerate the plan, and let the agents do the repetitive work. Humans stay in charge of intent and acceptance; agents handle the grind.
Brownfield vs Greenfield Development
If there’s one killer use case for Spec-Driven Development, it’s working on brand-new projects. SDD does an amazing job creating new software from fuzzy ideas and relatively short prompts. Suddenly, bringing software to life becomes effortless. Why spend time obsessing over wireframes when you can create a working app? Unsure if your idea is a good one? Why not build it and put it in the hands of people who can give you feedback?
Long term, there’s always an expectation that software matures, stabilizes, and improvements become more gradual. I think there’s a natural handoff between agentic patterns that make things and agentic patterns that perfect things. At the same time, if software is 10-100x cheaper to make, shouldn’t we be willing to throw it away 10-100x more often?
What if users of your app begin to expect frequent groundbreaking changes? What if they don’t even want to use the same app as their neighbor? Back to the philosophical shift.
What if hyper-personalized software is the future?
Specific platforms and apps melt away. Why buy a note-taking app? Why use a news aggregator? Why subscribe to a recipe planner? You could make all these yourself now. This is the vertigo we are all feeling in the developer community, and you’ve probably noticed that this section is mostly questions.
But when I’m talking about all the software that’s never been written, recognize that I’m really talking about the greenfield opportunities. Using AI to increase engineering productivity has its own set of challenges and will require more nuanced approaches. Google’s Jules is a great example of that.
What About Maintaining all This Software?
There’s a future rapidly approaching, and a present we’re all still digesting. AI makes it radically cheaper to write software, but without care, it doesn’t make owning that software any easier. Reliability, security, and long-term health are still hard problems.
CI/CD
SDD does provide somewhat of a handle on the chaos. Specs become the connective tissue between what we said we wanted
and what’s actually running in production
. Instead of thinking about CI/CD as just branches and pipelines, you have to start thinking about how changes to specs flow cleanly into code and back again.
In practice, that looks like keeping specs close to the work. New feature? You create or extend a spec first. The spec drives the design and the plan. Agents generate code, tests, and infrastructure from that plan. When the feature lands in main, you keep the spec alongside it as a durable record of intent.
You can absolutely map this onto your existing Git world. You don’t need a brand new branching strategy tomorrow. Feature branches can still map 1:1 to feature specs. Merges can still be code merges, with a lightweight discipline that says, if we changed behavior, we updated or added a spec
. Storage is cheap; a growing library of specs is a feature, not a bug.
Proactive Agents for Software Engineering
Beyond SDD, AI agents are useful again to manage this additional complexity and code. The philosophy here isn’t new. As AI rapidly developed, the industry had to learn how to use LLMs as judges. Capability scales with AI; trust has to scale with AI.
In this case, think of proactive agents whose entire job is to watch the development lifecycle:
Scanning for vulnerabilities in the generated code and dependencies.
Tracking version updates and incompatibilities across your stack.
Detecting spec drift, where the code and the documented intent start to diverge.
Surfacing technical debt that keeps showing up across specs and implementations.
Identifying dead or unused code that no longer maps to any living spec.
When that comes together, the human review bottleneck is alleviated.
People aren’t gone, but now using AI to scale all sides of development. Instead, they sit within an ongoing conversation among humans, specs, and agents. Humans own the intent and the tradeoffs. Specs capture that intent in a way agents can understand. Agents do the tedious work of keeping the repo aligned with what you actually meant to build, even as they’re rewriting large chunks of the codebase on your behalf.
What Software Hasn’t Been Written in the Enterprise
Up to this point, the blog has steered towards product development and consumer use cases. What about enterprise? How should an IT organization think about SDD? Should you expect a velocity bump? Yes.
As we discussed, this is easiest to see in greenfield work. The power lies in doing something that probably feels a bit uncomfortable. Writing code for things you wouldn’t have done before. This is a very new and fast-evolving space, so there’s plenty of caution to be had and even more to think about. Let’s push the envelope a bit to peek at what the future holds.
Data Science
I cut my teeth in the industry as a data scientist, so much of what I used to do can now be done with AI. Exploratory data analysis? I remember the old PyPI packages that attempted to solve for all of the boilerplate. Now? I use AI. These days, I use AI frequently to assess the business’s health and identify hidden trends. It’s not all perfect, but it is basically free.
What used to take days now takes just hours, with only intermittent involvement from me. You can’t just trust it. There’s a mindset shift from creating the analysis to overseeing it, and I’ve caught the AI making mistakes, but it remains worthwhile.
Another worthy topic is sending machine learning into production. Best way to refactor a Jupyter Notebook? AI. Best way to write data drift thresholds, break code into modules, develop containers, infrastructure, etc. AI. Does this mean you don’t need to know what you’re doing? Not at all. In fact, it makes expertise even more important. I can’t stress that enough.
You have to know what you’re looking for, be able to clearly articulate the goal, and quickly analyze achievement. Without a strong vision of MLOps, AI will just lead you into a dead end. With the vision, with the platform? Rocket fuel.
Data & AI Platforms
There’s never been a better time to be a builder. For teams working to create and manage data & AI platforms, Spec-Driven Development is a huge boost to velocity. You can define overarching principles, create MCPs for AIAD agents to access catalogs, metadata, and have AI agents do the heavy lifting.
Maybe that’s modernizing from R code running on Oracle extracts to Snowpark on native Snowflake data. Maybe that’s building a swarm of DevOps agents to drop ticket resolution time and increase uptime, or using Kiro to refactor your dbt transformation logic by plugging it into your semantic & dimensional data.
AI places huge demands on today’s platforms and provides a path to accelerating into that future.
Business Applications
Things like my mom’s app: custom UIs that incorporate business logic. Think about the competitive advantage you could have if you fold your business logic into a truly bespoke app that accelerates your core processes. You’re no longer dependent on vendors like Salesforce, Palantir, and SAS to build business apps, and you don’t need to share as much IP with your competition.
What’s Now and What’s Next?
So far, we’ve talked a lot about what could be. This is just the tip of the iceberg. Tools like Kiro, Claude Code, and Antigravity have gone viral for what they can do, and we’re now all dreaming of a future with them.
What’s next?
Real stories of success. Now is the time to bring together communities of developers, maximalists, and skeptics alike and start figuring out what opportunities lie ahead.
This is not the end of SaaS, but SaaS companies are on notice. There are many good reasons the commercial model will continue to exist. SaaS companies get to vibe-code too, after all. But, the intellectual property software moat they’ve built? Leaking badly.
At phData, we’re working quickly to collect stories of proven success across the industry and our clients.
Here are two recent examples that we’re really excited about:
Global Industrial Manufacturer
With a large sales force and specific needs, they didn’t want to buy AgentForce off the shelf. They wanted a custom sales agent experience. We delivered this incredibly quickly by combining our AI-assisted development acumen with the Snowflake platform, the company had already invested in. One year ago? No way they would’ve gotten where they are building, today it didn’t make sense to buy.
Regulated Life Sciences Services Firm
Our stakeholders were torn on the decision to build vs buy. The team was strongly considering purchasing Trunk Tools (P&ID software widely used in this space). Our team knew exactly what features our client needed, and used AIAD to rapidly deliver and excite stakeholders faster than they could get their credit cards out.










